





La fiabilidad de los test de antígenos y el teorema de Bayes
Hace unos días leí el parecer de un doctor sobre los test de antígenos. En una entrevista afirmaba que la fiabilidad estadística de estos test estaba vinculada a la incidencia, es decir, al número de infectados que hay en un período de tiempo dado cada 100.000 habitantes. El doctor consideraba que, cuando la incidencia es baja también baja la efectividad de los test detectando contagiados.
Más tarde y vía Twitter, otra doctora me indicó que este asombroso efecto estadístico era real y que se podía explicar mediante el teorema de Bayes, y me remitió a un artículo del periódico anglosajón The Guardian, donde aparece la correspondiente explicación. La doctora es fuente autorizada de la actualidad sanitaria en nuestro país y contribuye muy acertadamente a la divulgación científica en las redes sociales y, como la sigo, pues me hice eco del asunto. Aquí dejo el enlace al artículo que ella me pasó.
Y la traducción del artículo, por si alguien quiere echarle un ojo
El tema surgió de otro miembro de la comunidad Twitter, @CovidCO2, que solicitó una opinión sobre la entrevista al doctor Juan Vázquez Lago, médico del Hospital de Barbanza, en la Voz de Galicia.
La leí y le comenté a @CovidCO2 que había algunos puntos un tanto oscuros en las afirmaciones que sostenía el doctor. Puse como ejemplo esta: "Conforme disminuye la incidencia, también baja la probabilidad de que el test arroje un resultado positivo aún delante de un contagio".
A lo que añadí un comentario sobre mi desconocimiento de que la efectividad de los test de antígenos dependiese de la incidencia de la enfermedad en un determinado momento. Como la implicación me pareció grotesca, hice una pequeña chanza: dije que había que desconfiar de que llevasen dentro algún tipo de microchip que midiese estadísticas y que, en función de estas, modificase su comportamiento.
La doctora del Twitter también comentó su parecer acerca de la explicación del colega y dijo que se trataba de un fallido intento de explicar el teorema de Bayes.
Siguiendo el hilo argumental de la conversación por Twitter, traté de explicar que yo no encontraba ningún vínculo causal entre el resultado de "falso positivo" en un test de antígenos con que hubiese una determinada prevalencia. Y la doctora dijo que si lo había pero sin decir cuál. Y me pasó el enlace al artículo que puse antes.
Un poco contrariado, leí el artículo que mencionó la doctora -así por encima-, para poder contestarle convenientemente, y le dije esto: "Lo que afirma [el artículo] sobre la relación entre prevalencia y probabilidad es para el caso de cribados masivos y no para cuando se hacen test a sospechosos por tener síntomas o por ser contacto directo".
Me quedé petrificado ante el seco "no" que me espetó. Mi pequeño twitt merecía algo más que un "no". Aguardaba por una argumentación elaborada y lo que recibí fue una respuesta parca, minimalista, microscópica. No quise incomodarla y me puse a otras cosas, pero me quedé con esa sensación de tener una piedra metida en el zapato.

En cuanto tuve un rato libre leí de nuevo el artículo, esta vez con calma, a ver si se me había escapado algo, si había alguna cosa que no llegase a comprender en su totalidad. Es más, lo traduje para tener una visión holística del asunto. Aun así, por más vueltas que le di, sigo en mis trece: el artículo de The Guardian hace razonamientos correctos... pero la conclusión no es satisfactoria. Y esto es lo que -en mi opinión- hizo que ambos doctores sostuviesen (y pienso que muchos más también), una conclusión tergiversada.
Y esto es por lo que escribo estas líneas, un poco por llenar el vacío que me produjo aquel "no" rotundo y otro poco por descifrar el enigma de si la prevalencia influye o no en la fiabilidad de los test.
Empiezo con una crítica acerca del titular que, a mi entender, es un poco tendencioso. Traducido, dice así: "El oscuro teorema matemático que rige la fiabilidad de las pruebas Covid".
A ver, la fiabilidad de un test dependerá más de la calidad tecnológica con que se haya elaborado, de la durabilidad de sus componentes y del acierto cuando se utilice, que de un teorema matemático. Y este es el punto de donde parte el error de apreciación. El título no recoge con precisión lo que realmente dice el conjunto del documento. Yo lo titularía así: "El teorema matemático que desaconseja el uso de los test de antígenos en cribados masivos para detectar positivos".
Y es que el artículo explica bastante bien los pormenores del teorema de Bayes y también incluye algunas deducciones erróneas que son frecuentes en medicina y jurisprudencia (falacia del fiscal) por entenderlo equivocadamente. El autor deja para el final unos casos concretos de cálculo y deduce que el número de falsos positivos aumenta cuando la prevalencia es baja… pero aclara que, "…si realmente se está probando la población al azar".
Y aquí es donde está la clave del error: cuando los responsables sanitarios echan mano de los test para evaluar la positividad de un grupo de personas, éstas NO SON ELEGIDAS AL AZAR; previamente son considerados “sospechosos” de tener covid por diversos motivos (ser contacto directo, haberse hecho una prueba con anterioridad, encontrarse con síntomas…). Si falla esta premisa, entonces la conclusión que se pretende también fallará.
Voy a seguir con el mismo ejemplo que explica el artículo de "The Guardian" para que veáis aplicado el Teorema de Bayes. Primero expondré los ejemplos del artículo tal cual aparecen y luego los analizaré contextualizándolos de otra manera. A ver qué opináis.
En el artículo aparecen los siguientes datos:
Muestra: 1.000.000 de personas.
Probabilidad de base de estar infectadoo: Pi = 2%
Probabilidad de base de ser negativo: Ps = 98%
Probabilidades condicionadas:
De que el test de antígenos dé positivo con una persona infectada: P+|Pi = 90%
De que el test de antígenos dé negativo con una persona infectada: P-|Pi = 10%
De que el test de antígenos dé positivo con una persona sana: P+|Ps = 0,1%
De que el test de antígenos dé negativo con una persona sana: P-|Ps = 99,9%
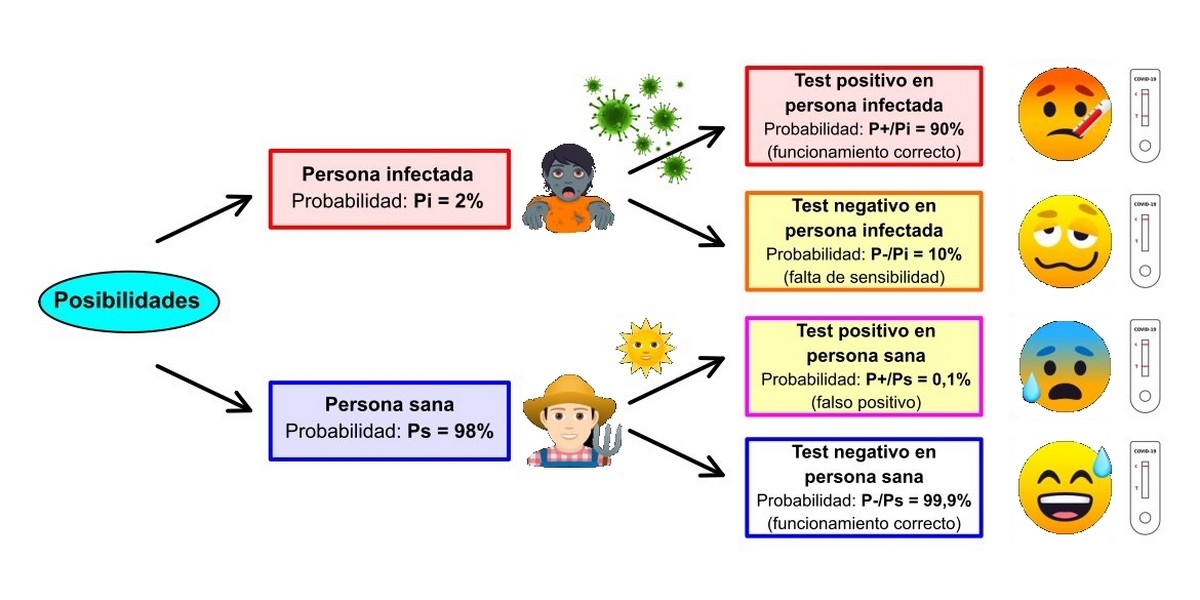
Del esquema anterior vemos que hay dos posibilidades que conducen a un fallo en el diagnóstico (las de color amarillo): que el test no reaccione ante una persona infectada y dé negativo o que salga un resultado positivo ante una persona completamente sana. Ambas fallas son inevitables puesto que los test no son perfectos. Es por esto que los fabricantes procuran que sus test sean lo más fiables posible y esto lo consiguen ajustando óptimamente dos parámetros:
- La sensibilidad. Se puede decir que es la probabilidad de tener un resultado positivo en pacientes que realmente tienen la enfermedad. Cuánto más sensible sea el test, más fácilmente detectará la presencia del virus, a pesar de que la carga viral del sujeto no sea muy alta. En nuestro caso hemos considerado un 90%, siguiendo los parámetros del artículo analizado.
- La especificidad. Es la probabilidad de tener un resultado negativo en pacientes que no tienen la enfermedad. Expresa lo selectivo que es el test para un solo virus, es decir, que el test no dará falsos positivos con otros virus o agentes infecciosos. Es un parámetro que indica la precisión del ensayo y la valoramos, como ejemplo, en un 99,9%.
E insisto en que estos porcentajes los he cogido tal cual del artículo de The Guardian.
Ahora toca hablar un poco del Teorema de Bayes. Lo emplearé para calcular las probabilidades inversas a las del esquema (probabilidades a posteriori), es decir, queremos saber cuánto es de probable que tengamos una persona sana después de salirle positivo el test (Ps|P+) y cuánto es de probable que tengamos un contagiado después de salirle negativo el test (Pi|P-). Por experiencia sabemos que lo primero es mucho más difícil que lo segundo. De hecho, es muy frecuente que aparezcan contagiados ocultos tras hacer una segunda prueba tipo PCR (que es mucho más sensible que los test de antígenos).
Y estas probabilidades nos las proporciona el teorema de Bayes. Sólo debemos recurrir a las siguientes fórmulas:

Calculamos primero la probabilidad de que una persona elegida al azar obtenga un resultado positivo en el test (P+).
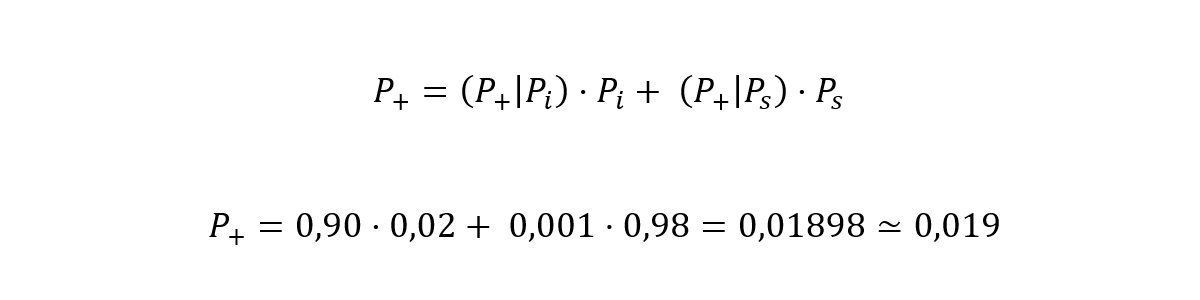
O sea, que la probabilidad de que una persona cualquiera dé positivo al ser sometida a un test de antígenos es del 1,9%.
Hacemos lo mismo para calcular la probabilidad de que una persona elegida al azar obtenga resultado negativo al hacer el test (P-).
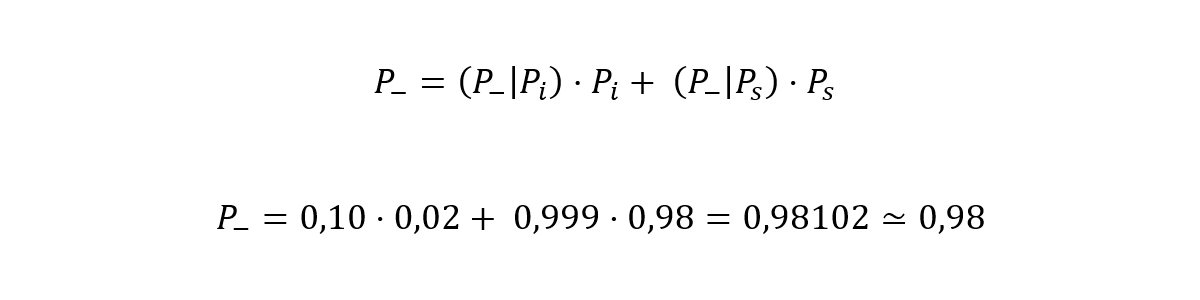
O sea, que la probabilidad de que una persona cualquiera dé negativo al ser sometida a un test de antígenos es del 98,1%, (justo el mismo valor que si restamos 100% – 1,9%, el valor de P+). Ya estamos en la recta final. Calculo la probabilidad de que tengamos una persona sana después de salirle positivo el test (Ps|P+) (o sea, de tener un falso positivo):
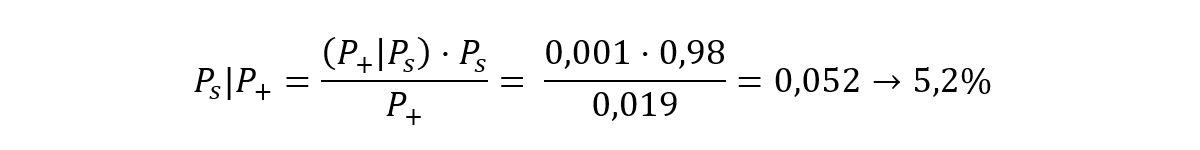
Y la probabilidad de que la persona esté infectada a pesar de salir negativo el test:
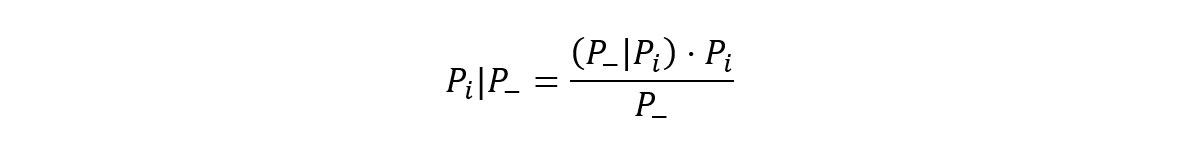
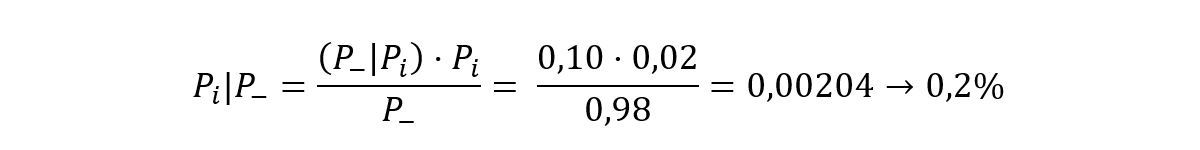
Este resultado es paradójico: el Teorema de Bayes indica que, aunque las dos probabilidades son bajas, es mucho más probable que un individuo esté sano a pesar de dar positivo en el test que que esté infectado a pesar de salir un test negativo. Y esto es así porque son muchas más las personas sanas que infectadas y porque estamos cogiendo candidatos al azar, sin hacer ninguna consideración, como en un cribado masivo.
La realidad contradice el hecho anterior, es decir, que es más frecuente que un infectado pase el test que una persona sana arroje un resultado positivo. Esta aparente contradicción se explica porque las personas que recurren a los test no van por azar, sino que lo hacen o bien porque tienen síntomas compatibles o bien porque han sido contactos estrechos. Esto cambia por completo las probabilidades a priori y, con ello, los resultados de la probabilidad condicionada.
Ahora analizaré los dos casos expuestos en el artículo de The Guardian y pondré tres ejemplos más que servirán de contrapunto.
Caso Nº1 – Prevalencia de la enfermedad relativamente alta:
Muestra: 1.000.000 de personas.
Probabilidad de encontrar un infectado: Pi = 2%
Esto conlleva a que la población se reparta así:
Personas infectadas: 20.000
Personas sanas: 980.000
Probabilidad de que un infectado dé positivo en el test: P+|Pi = 90% (→ 0,90)
Probabilidad de que el test arroje un falso positivo: P+|Ps = 0,1% (→ 0,001)
(Son los mismos valores que consideramos desde el principio)
Al hacer 1.000.000 de test (uno a cada persona), se obtendrán los siguientes resultados:
Nº de test positivos: 0,90·20.000 + 0,001 · 980.000 = 18.980
Nº de infectados que no ha detectado el test: 0,10 · 20.000 = 2000
Nº de test que dan falsos positivos: 0,001 · 980.000 = 980
Porcentaje test de falsos positivos: 980 / 18.980 = 0,0516 → 5,16%
Para hacer este porcentaje, el autor del artículo no divide entre el número de test con resultado positivo (18.980), sino que lo hace entre el total de positivos que deberían salir en las pruebas: 20.000 + 980 = 20.980. En este aspecto se equivoca porque supone una fiabilidad del 100% del test a la hora de encontrar infectados (recordemos que se presupuso del 90%). El caso es que este defecto no influye demasiado en las cuentas. Lo que hace el autor es equivalente a considerar que test detecta el 100% de infectados y no el 90%.
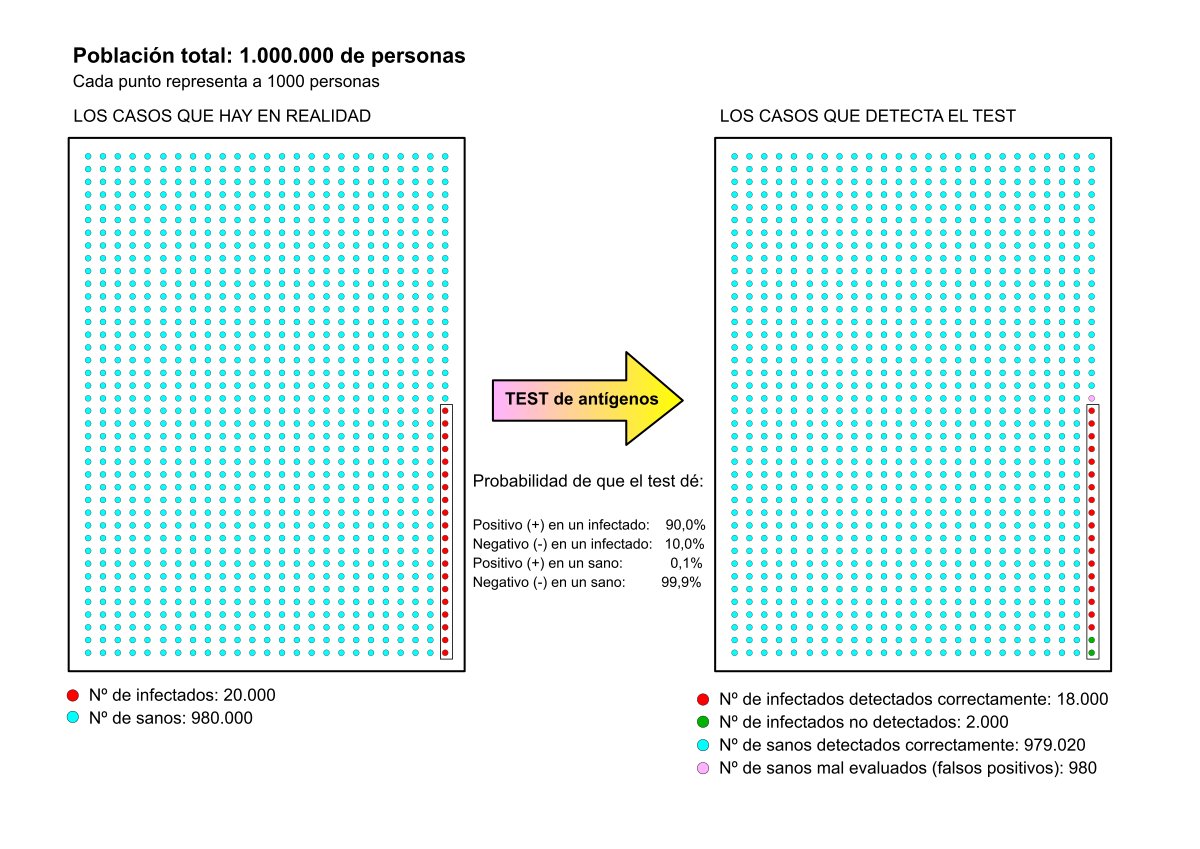
Caso Nº2 – Prevalencia de la enfermedad baja:
Muestra: 1.000.000 de personas.
Probabilidad de encontrar un infectado: Pi = 0,3%
Esto conlleva a que la población se reparta así:
Personas infectadas: 3.000
Personas sanas: 997.000
Probabilidad de que un infectado dé positivo en el test: P+|Pi = 90%
Probabilidad de que el test arroje un falso positivo: P+|Ps = 0,1%
Al hacer 1.000.000 de test (uno a cada persona), se obtendrán las siguientes cantidades:
Nº de test con resultado positivo: 0,90 · 3.000 + 0,001 · 997.000 = 3.697
Nº de infectados que no ha detectado el test: 0,10 · 3.000 = 300
Nº de falsos positivos: 0,001 · 997.000 = 997
Porcentaje de falsos positivos: 997 / 3.697 = 0,2697 → 27%
Y aquí tenemos la paradoja, que parece que con una prevalencia baja el porcentaje de falsos positivos aumenta (hemos pasado del 5% en el caso nº1 al 27% en el caso nº2). El autor indica que esto se debe a que se han cogido personas al azar pero, a pesar de reconocerlo, la conclusión es taxativa: a bajas prevalencias los test de antígenos fallan mucho.
Ahora voy a plantear de otro modo más realista los mismos casos anteriores. Y veremos lo que sucede.
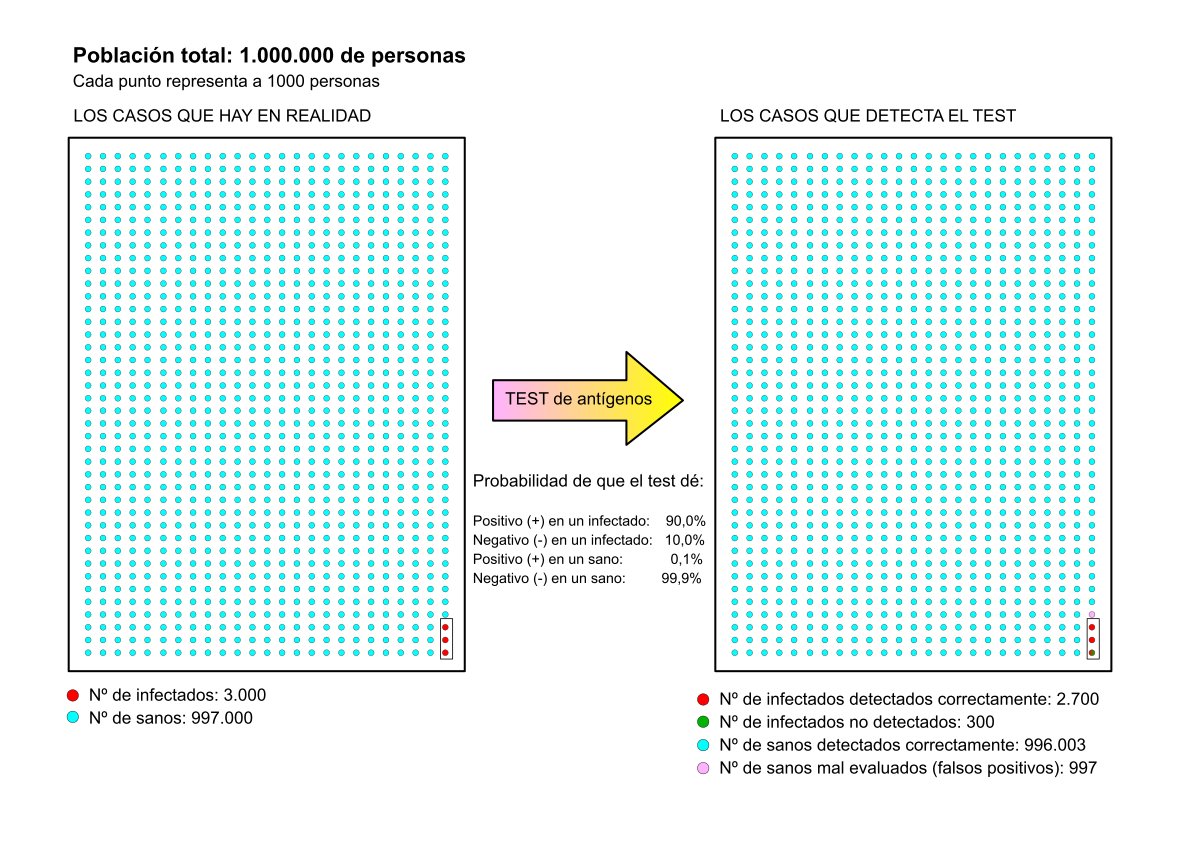
Caso Nº3 – Prevalencia de la enfermedad relativamente alta (igual que en el caso nº1):
Muestra: 1.000.000 de personas.
Probabilidad de encontrar un infectado: Pi = 2%
Esto conlleva a que la población se reparta así:
Personas infectadas en total: 20.000
Personas sanas en total: 980.000
Probabilidad de que un infectado dé positivo en el test: P+|Pi = 90%
Probabilidad de que el test arroje un falso positivo: P+|Ps = 0,1%
Sospechosos de infección por sintomatología o posible contacto: 100.000 (he considerado esta cantidad teniendo en cuenta que de cada 5 pruebas PCR realizadas, aproximadamente una es positiva). La probabilidad de base de encontrar un infectado ya no es del 2% sino del 20%. Se harán, entonces, 100.000 test de antígenos de los que se obtendrán las siguientes cantidades:
Nº de test con resultado (+): 20.000 (son test, no todos están infectados)
Nº de test con resultado (-): 80.000 (son test, no todos están sanos)
(Aquí va al pelo aquello de que “ni están todos los que son, ni son todos los que están”).
Empleo de nuevo Bayes para calcular el número de personas realmente infectadas cuyo test ha sido positivo:
Nº de infectados detectados por el test = 20.000 · (Pi|P+)
Pi|P+ = [(P+|Pi) · Pi] / P+ = [0,90 · 0,02] / 0,01898 = 0,948
Nº de infectados detectados por el test: 20.000 · (Pi|P+) = 20.000 · 0,948 = 18.967 personas.
Nº de falsos positivos = 20.000 - 18.967 = 1.033
Porcentaje de falsos positivos = 1.033 / 20.000 = 0,0516 → 5,16%
Curiosamente, sale un valor similar al considerado en el caso nº1.
Empleo de nuevo Bayes para calcular el número de personas realmente sanas cuyo test ha sido negativo:
Nº de test negativos = 80.000
Nº de personas sanas detectadas correctamente = 80.000 · (Ps|P-)
Ps|P- = [(P-|Ps) · Ps] / P- = [0,999 · 0,98] / 0,98102 = 0,99796
Nº de sanos detectados correctamente = 80.000 · (Ps|P-) = 80.000 · 0,99796 = 79.837
Nº de personas que dieron negativo en el test pero no están sanos
(o sea, contagiados que no se han sido detectados como tal) = 80.000 - 79.837 = 163
Podemos comprobar que el número total de personas infectadas que han hecho el test no es 20.000. Al coger una muestra de 100.000 sospechosos, algunos se han quedado fuera. Podemos estimar cuantos:
Nº de infectados que han hecho el test = 18.967 detectados + 163 que no se detectaron = 19.130
Quedaron 20.000 – 19.130 = 870 infectados sin pasar ninguna prueba que, seguro, estarán propagando tan tranquilamente el virus entre sus contactos y allegados. En total habrá 870 + 163 = 1·033 infectados que no se han sido detectados.
Con el cribado masivo que se proponía en el caso nº1 quedarían fuera de cómputo un total de ¡2000 casos! Y aquí tenemos otra paradoja. Resulta mucho mejor seleccionar sospechosos que hacer cribados masivos. Con la selección de sospechosos quedan ocultos menos infectados.
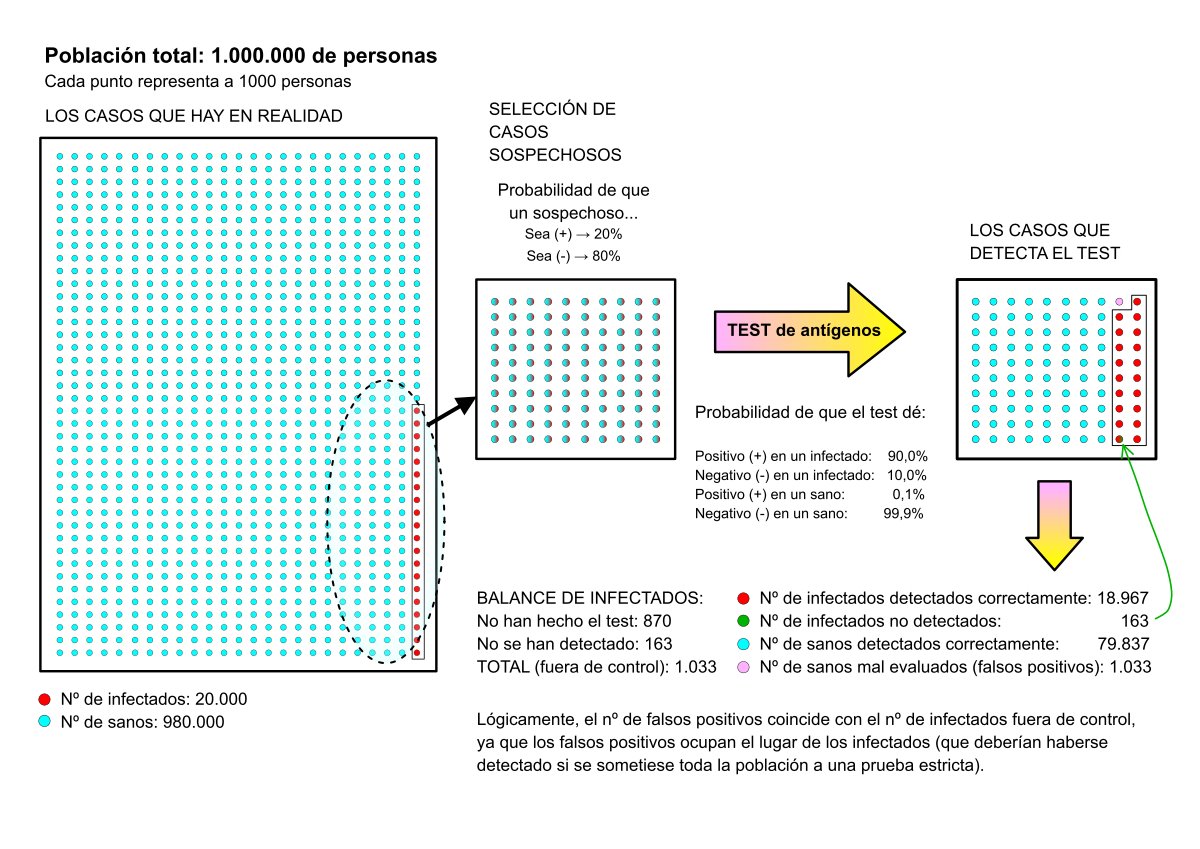
Caso Nº4 – Prevalencia de la enfermedad baja, (como en el caso nº2):
Muestra: 1.000.000 de personas.
Probabilidad de encontrar un infectado: Pi = 0,3%
Esto conlleva a que la población se reparta así:
Personas infectadas en total: 3.000
Personas sanas en total: 997.000
Probabilidad de que un infectado dé positivo en el test: P+|Pi = 90%
Probabilidad de que el test arroje un falso positivo: P+|Ps = 0,1%
Sospechosos de infección por sintomatología o posible contacto: 15.000, lo mismo que en caso nº3. La probabilidad de base de encontrar un infectado ya no es del 2% sino del 20%, como se dijo en el caso nº3.
Nº de test con resultado (+): 3.000 (son test, no todos están infectados)
Nº de test con resultado (-): 12.000 (son test, no todos están sanos)
Empleo de nuevo Bayes para calcular el número de personas realmente infectadas cuyo test ha sido positivo:
Nº de infectados detectados = 3.000 · (Pi|P+)
Pi|P+ = [(P+|Pi) · Pi] / P+ = [0,90 · 0,02] / 0,01898 = 0,948
Nº de infectados detectados por el test = 3.000 · 0,948 = 2.844 personas.
Nº de supuestos infectados (falsos positivos) = 3.000 – 2.844 = 156.
Porcentaje de falsos positivos = 156/3.000 = 0,052 → 5,2%
Y este es un valor muy diferente al que salió en el caso nº2 (análogo a este, pero que dio un extraordinario 27%), sino que sale un valor muy parecido al caso nº3.
Empleo de nuevo Bayes para calcular el número de personas realmente sanas cuyo test ha sido negativo:
Nº de personas sanas detectadas correctamente = 12.000 · (Ps|P-)
Ps|P- = [(P-|Ps) · Ps] / P- = [0,999 · 0,98] / 0,98102 = 0,99796
Nº de sanos detectados correctamente = 12.000 · 0,99796 = 11.976
Nº de contagiados que no se han detectado = 12.000 - 11.976 = 24
Podemos comprobar que el número total de personas infectadas que han hecho el test no es 3.000. Al coger una muestra de 15.000 sospechosos, algunos se han quedado fuera. Podemos estimar cuantos:
Nº de infectados que han hecho el test = 2.844 detectados + 24 que no se detectaron = 2.868
Quedaron 3.000 - 2.868 = 132 infectados sin pasar ninguna prueba que, seguro, estarán propagando en virus entre sus contactos y allegados.
Con el cribado masivo que se proponía en el caso nº2 quedarían fuera de cómputo un total de ¡300 casos! Y aquí tenemos otra vez la paradoja. Resulta mucho mejor seleccionar sospechosos que hacer cribados masivos aún con prevalencias bajas. Con la selección de sospechosos quedan ocultos menos infectados.
En los casos nº3 y nº4 he considerado como 1/5 la probabilidad de base de que una persona esté infectada habiendo sido sospechosa -y por tanto que será seleccionada para hacer un test de antígenos-, valor independiente de la prevalencia. Y esta es la clave del asunto: que la probabilidad de base es independiente de la prevalencia. Comprobaré este hecho en el caso que expongo a continuación.
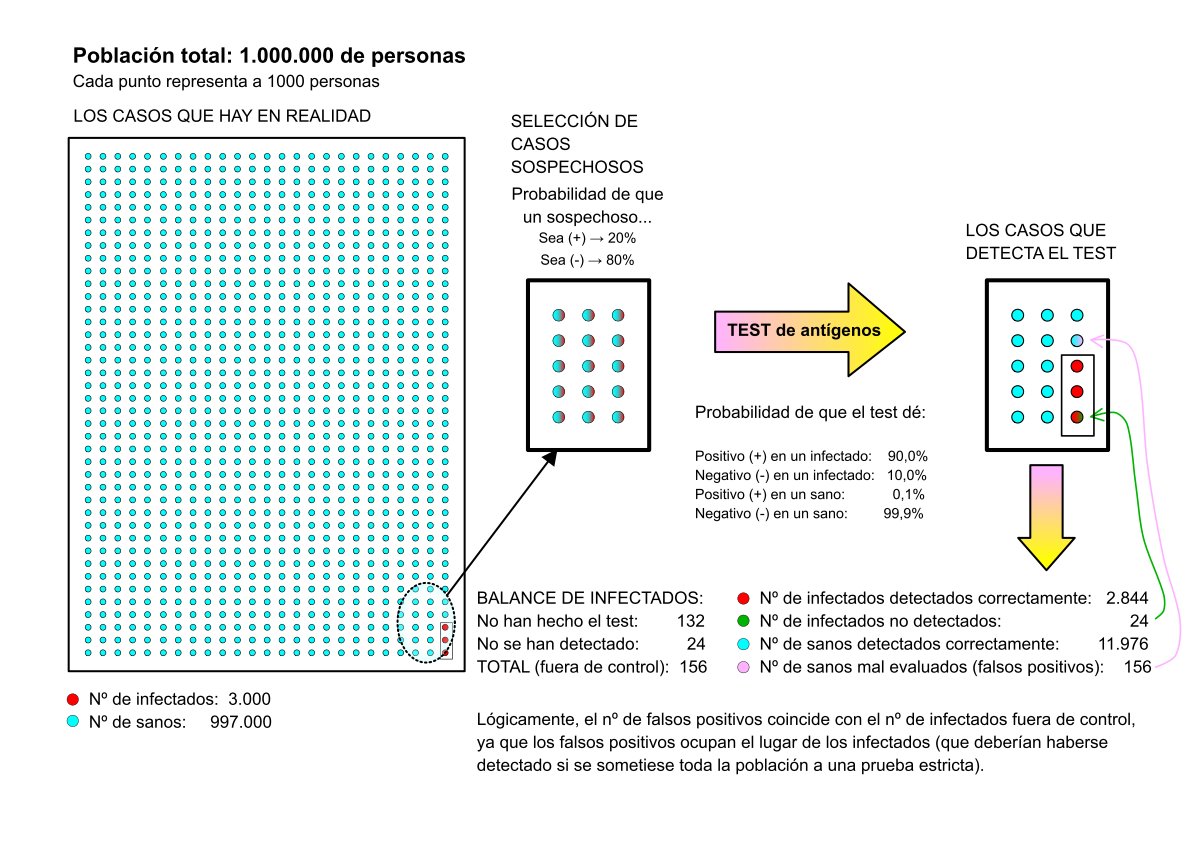
Caso Nº5 – Prevalencia de la enfermedad baja, como en los casos nº2 y nº4 y probabilidad de ser sospechoso de infección del 10% (1/10, la mitad que en el caso 4):
Ahora consideraré que la probabilidad de base se puede equiparar a la positividad media que arrojan los test hechos en anteriores pruebas. La cuestión que quiero estudiar es si se podría inferir la afirmación de partida: que ante una menor prevalencia la positividad se reducirá y, por tanto, aumentará el porcentaje de falsos positivos y, en consecuencia, la eficiencia de los test.
Muestra: 1.000.000 de personas.
Probabilidad de encontrar un infectado: Pi = 0,3%
Esto conlleva que la población se reparte así:
Personas infectadas en total: 3.000
Personas sanas en total: 997.000
Probabilidad de que un infectado dé positivo en el test: P+|Pi = 90%
Probabilidad de que el test arroje un falso positivo: P+|Ps = 0,1%
Sospechosos de infección por sintomatología o posible contacto: 30.000. La probabilidad de base de encontrar un infectado la he considerado ahora del 10%, como adelanté al principio.
Nº de test con resultado (+): 3.000 (son test, no todos están infectados)
Nº de test con resultado (-): 27.000 (son test, no todos están sanos)
Empleo de nuevo Bayes para calcular el número de personas realmente infectadas cuyo test ha sido positivo:
Nº de infectados detectados = 3.000 · (Pi|P+)
Pi|P+ = [(P+|Pi) · Pi] / P+ = [0,90 · 0,02] / 0,01898 = 0,948
Nº de infectados detectados por el test = 3.000 · 0,948 = 2.844 personas.
Nº de falsos positivos = 3.000 – 2.844 = 156.
Porcentaje de falsos positivos: 156 / 3.000 = 0,052 → 5,2%
El mismo valor que antes.
Empleo de nuevo Bayes para calcular el número de personas realmente sanas cuyo test ha sido negativo:
Nº de personas sanas detectadas correctamente = 27.000 · (Ps|P-)
Ps|P- = [(P-|Ps) · Ps] / P- = [0,999 · 0,98] / 0,98102 = 0,99796
Nº de sanos detectados correctamente: 27.000 · 0,99796 = 26.945
Nº de contagiados que no se han detectado = 27.000 - 26.945 = 55
Estimamos, como antes, el nº de infectados que no han hecho ningún test:
Nº de infectados que han hecho el test = 2.844 detectados + 55 que no se detectaron = 2.899 infectados que han hecho el test.
Quedaron 3.000 - 2.899 = 101 infectados sin pasar ninguna prueba.
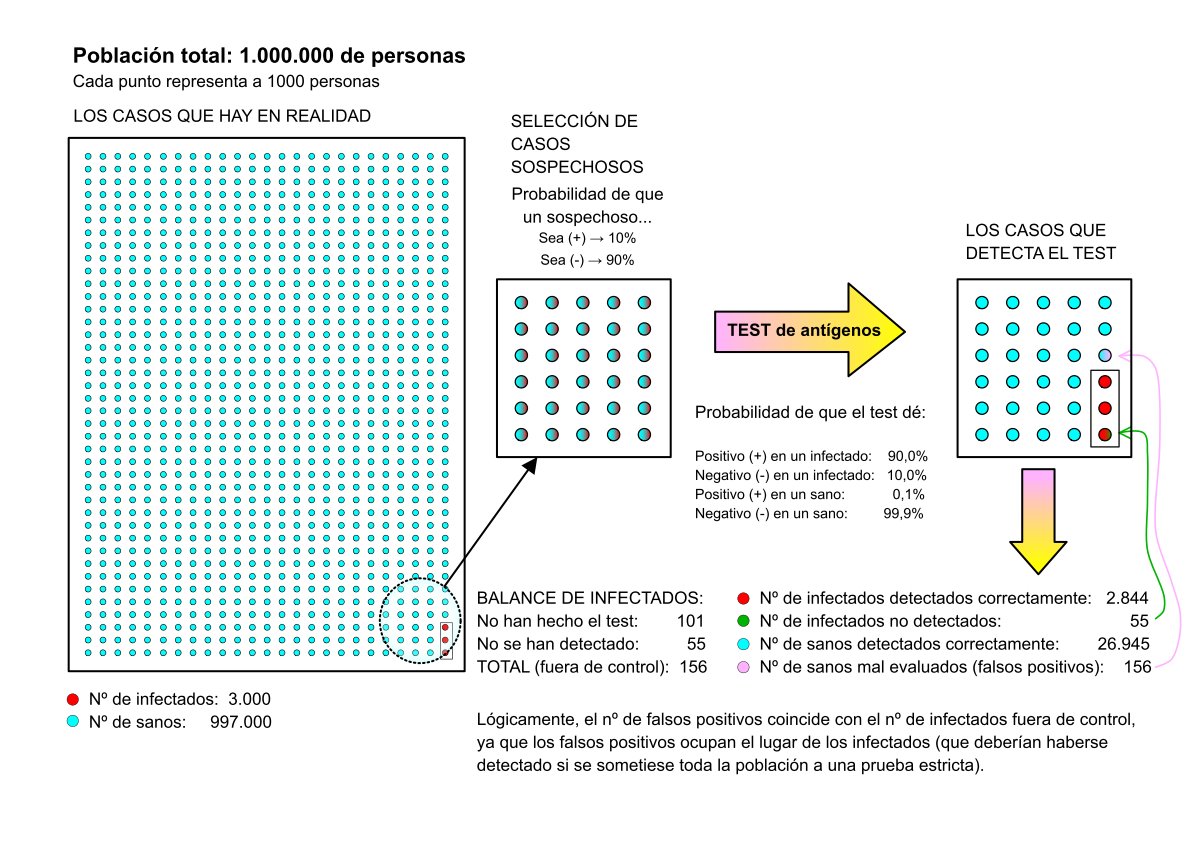
Es curioso que, al coger un grupo mayor de sospechosos quedan fuera de detección menos infectados, pero no muchos menos. En el caso nº4, con 15.000 seleccionados para hacer el test, quedaban 132 infectados sin hacer las pruebas. Ahora, con 30.000 seleccionados (el doble), quedan 101 sin hacer la prueba. Compensa, por tanto, escoger bien a los sospechosos de tener la enfermedad antes de someterlos a un test de antígenos. Al fin y al cabo, el número de contagiados que estarán fuera de control será el mismo.
Y por este mismo motivo saldría caro repetir la misma prueba a aquellas personas que han dado negativo de primeras. De los 27.000 negativos que se consideraron en este último análisis, solo 2 de cada 1000 podrían aparecer como auténticos positivos en una segunda vuelta.
Y una última consideración: todo este análisis estadístico se basa en medir probabilidades que son, por naturaleza, cambiantes. Dependen mucho de las variantes infecciosas que predominen, de la transmisividad, de los protocolos marcados para contener la propagación y, en definitiva, de decisiones humanas. Por ejemplo, si la gente decide ocultar que está infectada o se niega a hacer un test, pues no hay probabilidad que valga.