







Matemáticas para una epidemia - Propagación del SARS-CoV-2
Durante estos días de confinamiento doméstico por la pandemia Covid-19 los medios de comunicación no paran de ofrecer datos y estadísticas. Se cuentan los infectados por cientos de millares y, sin duda, llegarán a los millones. El número de fallecidos se augura muy elevado aunque en unos países más que en otros. Unos son más escrupulosos que otros anotando el número de enfermos y el número de muertos. En algunas naciones pesa más la apariencia que la ciencia y ocultan fallecimientos para fingir que tienen la enfermedad bajo control. Algunos políticos son partidarios de falsear los índices de afectación para mostrar organización social, fortaleza sanitaria y eficiencia técnica hacia el extranjero. Internamente se evita el pánico y se palían los daños económicos, pues la gente se resigna al contagio para salvaguardar sus puestos de trabajo. Otros prefieren ser realistas y contabilizan los casos tan estrictamente como pueden para saber a qué se atienen y así tomar decisiones acertadas en aras de contener al virus. Creo que es más acertada la última actitud.
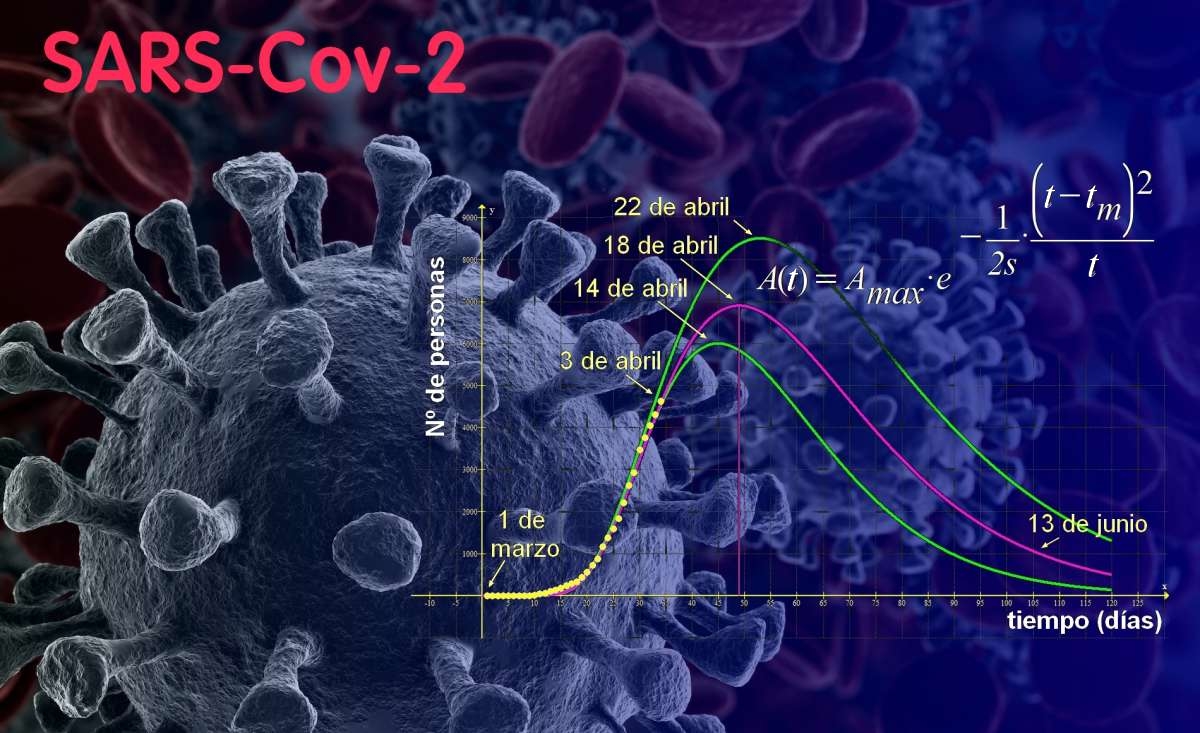
He leído algunas teorías que tratan de predecir la evolución de esta enfermedad y he tenido tiempo para reflexionar sobre las condiciones de propagación de la misma. Sigo las estadísticas oficiales desde el principio y me ha llamado la atención que se prioricen los datos de los casos acumulados hasta una fecha frente a los datos de casos activos por día. En una conocida página web de información estadística, Woldometer, se recogen los datos diarios de muchos países donde se ha extendido el virus SARS-CoV-2. En sus gráficas se observa como la curva que mejor se comporta (en cuanto a parametrización matemática se refiere), es la de los casos activos diarios.
No todos los países, como antes dije, tienen la misma fiabilidad, por lo que me centré en aquellos que diagnosticaron pronto la enfermedad y tomaron medidas para detenerla al poco tiempo de detectarla. Uno de esos países que ha demostrado más eficacia y transparencia es Corea del Sur. Allí se demoraron muy poco en hacer test masivos para saber con certeza cómo se expandía la epidemia. A raíz de su eficacia, tomaron medidas acertadas que convirtieron a Corea del Sur en el primer país del mundo en contener la Covid-19, con un margen muy pequeño de afectados y fallecidos.
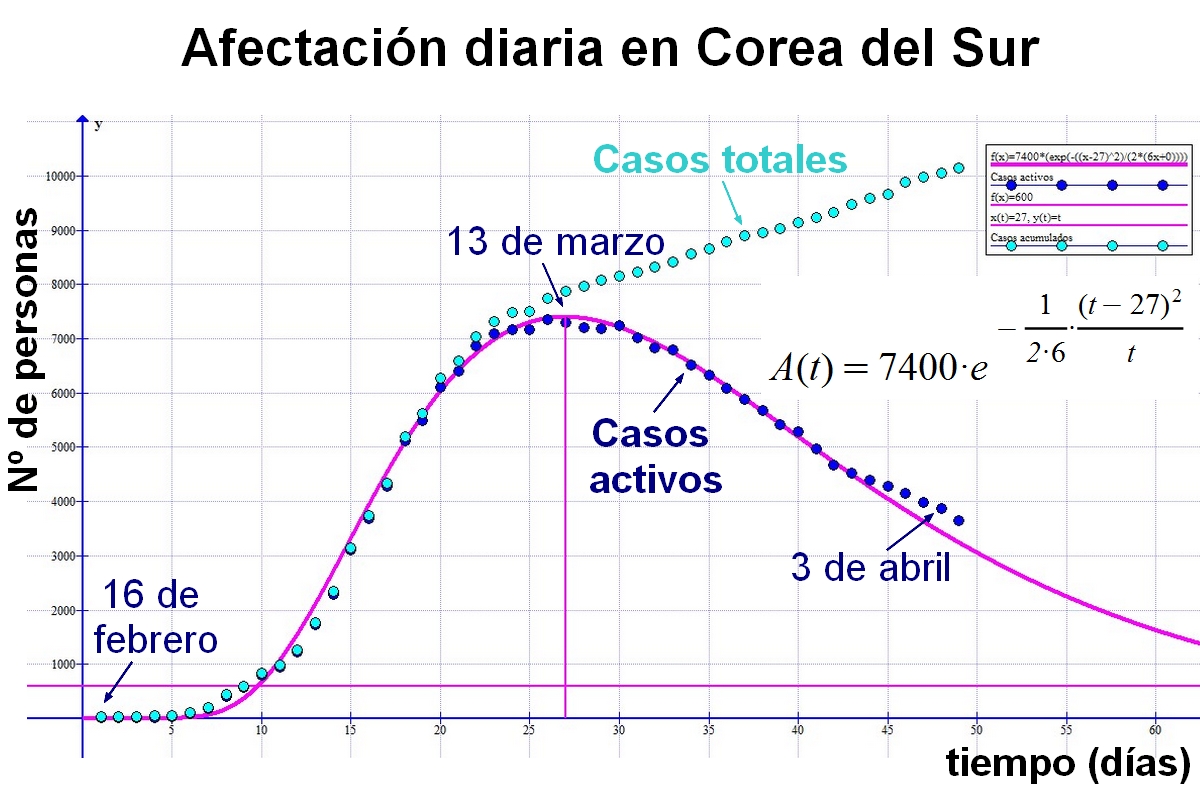
Por este motivo anoté los datos de Corea del Sur y los ajusté a una curva que, por intuición, me pareció la más adecuada. Reflexioné sobre las variables de las que depende el comportamiento y el análisis consiguiente me quedó bastante ajustado a la realidad. Seguí apuntando los datos diariamente... y no tuve que corregir: la gráfica seguía siendo válida un día tras otro.
Entonces empecé a hacer cuentas y llegué a la conclusión de que en todas las regiones del mundo en donde se recogen datos de forma fidedigna la curva de afectados se ajusta muy bien a la siguiente fórmula:
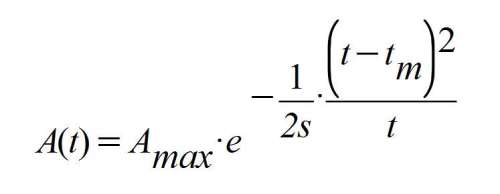
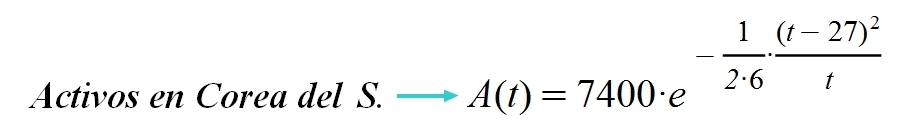
La función A(t) proporciona la cantidad de personas que tienen el coronavirus cada día (los llamados "casos activos"), siendo dependiente de la variable temporal "t". El parámetro "Amax" indica el número máximo de personas que han contraído la enfermedad en un día (el célebre "pico" para A(t). El parámetro "s" evalúa la transmisibilidad de la enfermedad y "tm" es el día en que se produce el número máximo de afectados "Amax".
Aquí está la previsión para España:
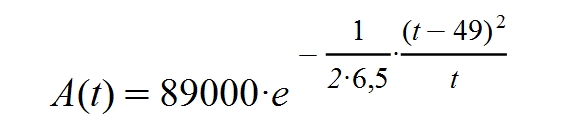
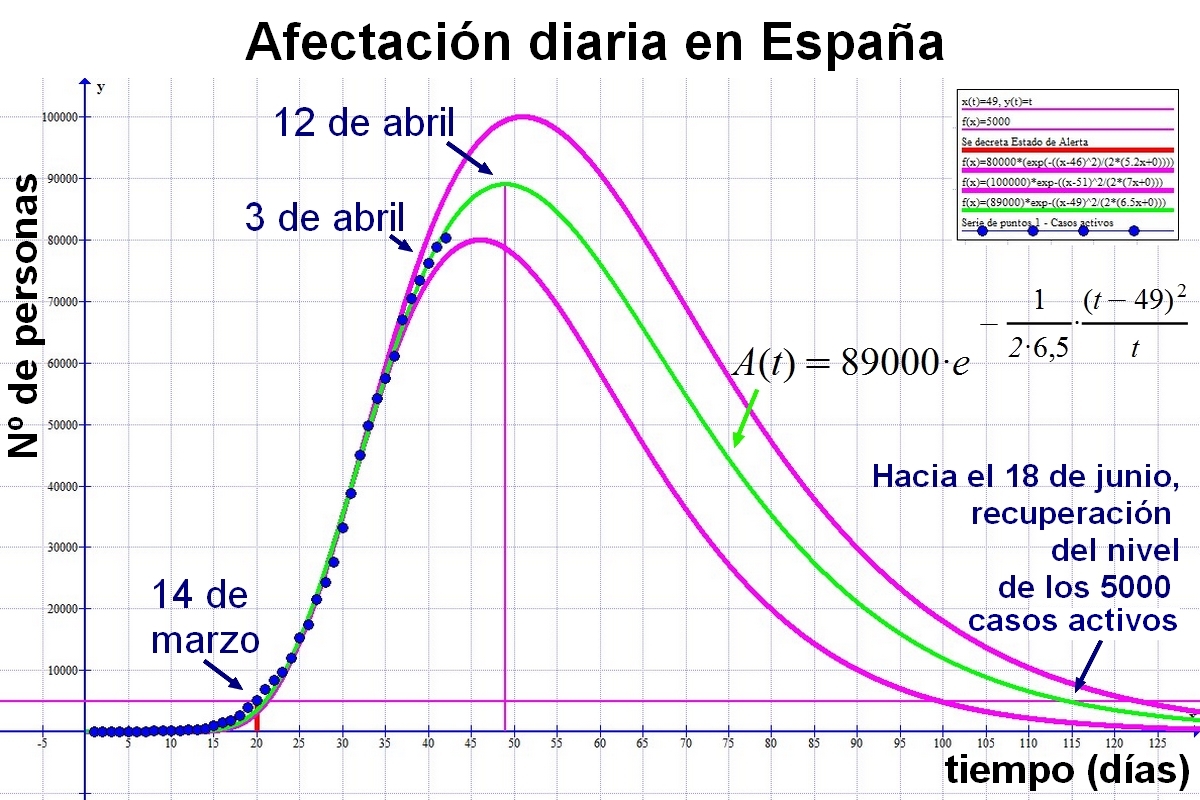
Aquí está la previsión para Galicia:
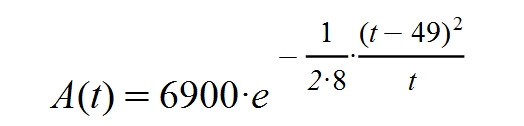
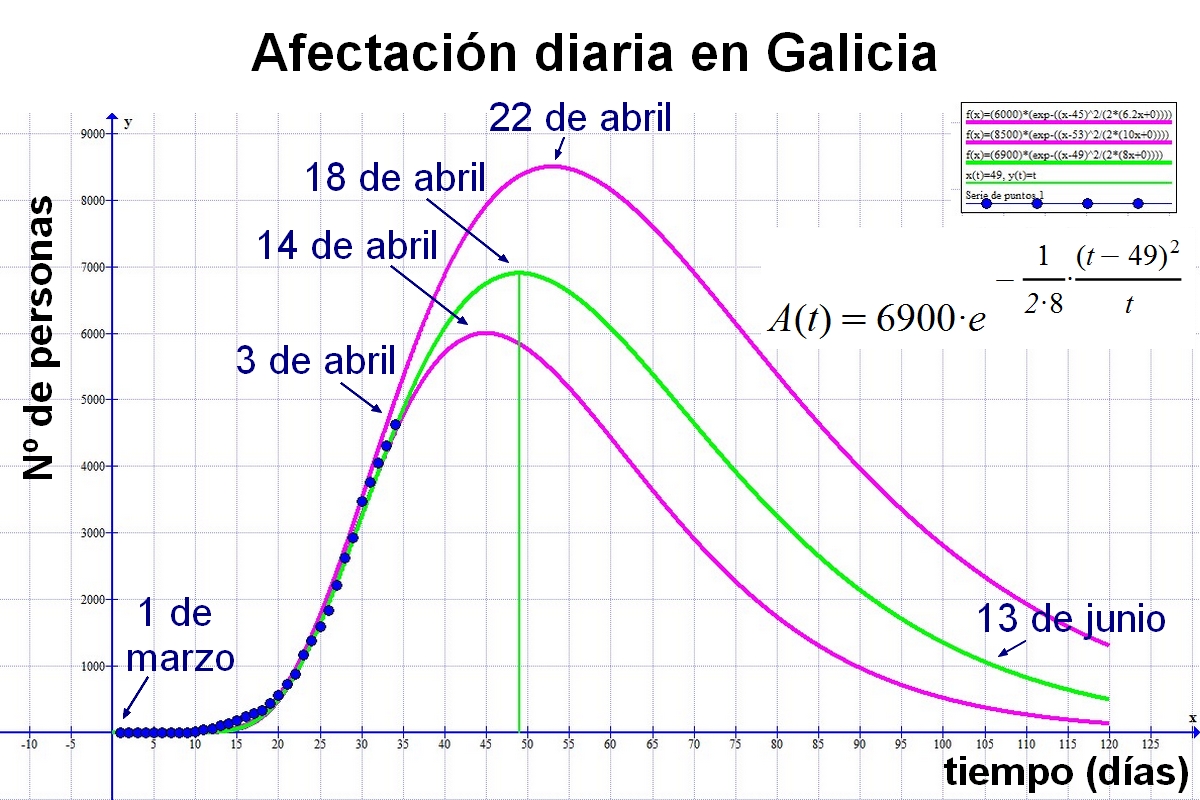
A continuación explicaré el origen de esta función.
Para comenzar con el análisis, he supuesto una población muy grande que solo se va a contagiar parcialmente. Siempre va a haber individuos no afectados en una cantidad significativa. También he considerado tres funciones destacables en la propagación de la dolencia:
A(t), que es, como antes dije, el número de casos activos cada día.
E(t), que indica la cantidad de enfermos aislados o confinados.
X(t), indica la cantidad de personas totales expuestas al agente patógeno en cada instante.
S(t), que refleja la diferencia entre las personas susceptibles de contraer la enfermedad (o personas expuestas), menos las afectadas y aisladas.
Hemos supuesto que la cantidad neta de personas susceptibles de enfermar, S(t), son propensas a contagiarse de otras personas no confinadas pero enfermas (con o sin síntomas). Por este motivo he pensado que se deben cumplir las siguientes igualdades:
S(t) = X(t) – E(t)
X(t) = α.A(t)
Donde "α" es un factor que indica la proporción entre los afectados que pueden transmitir la enfermedad y los expuestos a contraerla.
E(t) = β.A(t)
Donde "β" es un factor de proporcionalidad entre los enfermos reales que hay y los que están aislados. Al suponer β < 1, estamos diciendo que hay enfermos que no están siendo considerados como tal. Si β > 1, entonces indicamos que hay más personas consideradas "enfermas" que personas realmente afectadas. Esto podría suceder si tenemos falsos positivos que están siendo tratados como pacientes auténticos o personas curadas que todavía se están contabilizando como activas.
S(t) = α.A(t) - β.A(t) = (α - β).A(t)
También hemos supuesto que la variación diaria de afectados es proporcional al número de personas susceptibles S(t):
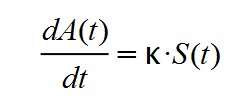
De esta forma se tiene que:
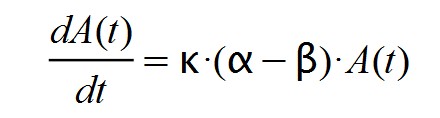
Al principio de la epidemia sucede que α >> β y, por tanto, α – β > 0. Si suponemos (erróneamente) que el factor k.( α – β) se mantiene constante y positivo en esta etapa, llegaremos a la siguiente ecuación diferencial:
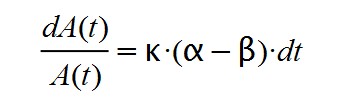
Cuya solución es una función exponencial creciente, habitual de otros modelos de crecimiento que suceden en la naturaleza, como la reproducción descontrolada y sin límites o las reacciones nucleares en cadena.
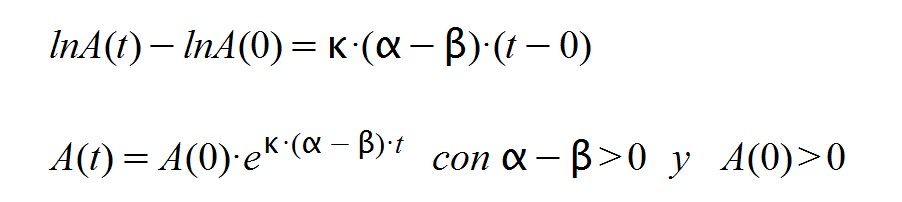
Cuando la enfermedad ya ha afectado a una gran cantidad de población y se ha generado inmunidad, los factores α y β cambian de tal forma que α < β. Esto es así porque la tasa de contagios ahora es menor que la tasa de curaciones. Por eso:
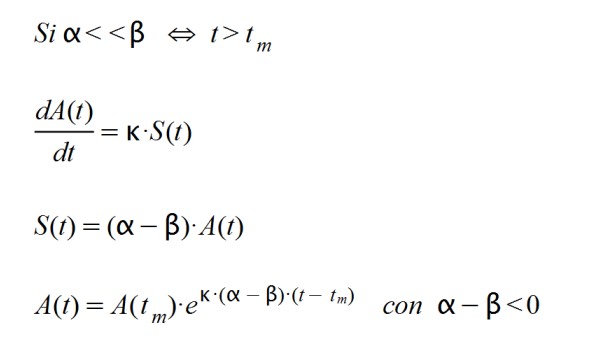
Resulta que A(t) responde en este segundo caso a una función exponencial decreciente ya que su exponente es negativo. El tiempo "tm" es el punto donde la función adquiere su valor máximo, A(tm) desde el cual desciende hasta cero.
Vemos con claridad que ambas consideraciones tienen que conjugarse si queremos explicar el comportamiento de la epidemia actual. Lo primero que debemos tener en cuenta es que el producto k.( α – β) debe variar con el tiempo y pasar de positivo a negativo. Justo cuando α = β el producto vale cero. En ese caso, la función debe alcanzar su valor máximo (el famoso "pico" de afectación), ya que ahí resultará que dA(t)/dt = 0.
Por otra parte sabemos que a tiempo cero el parámetro a debe tender a infinito, puesto que en ese momento ya hay personas susceptibles de ser contagiadas sin haber todavía casos registrados ni enfermos confinados.
En t = 0 sucede que S(t) = α.A(t) – E(t) > 0, con A(t) = 0 y E(t) = 0.
Otra consideración más a tener en cuenta es que la enfermedad debe menguar al cabo de cierto tiempo ya que mucha gente adquirirá inmunidad (y alguna morirá), por lo que son personas que no se podrán contagiar de nuevo. Por ello he pensado que debería haber un factor negativo en la función exponencial. Lo propongo de la siguiente forma:
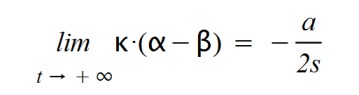
He escogido esta forma "–a/2s" por simplificación de cálculo (y por significación del mismo), que después explicaré.
En consecuencia, como parametrización del producto k.( α – β) he tomado la siguiente aproximación:
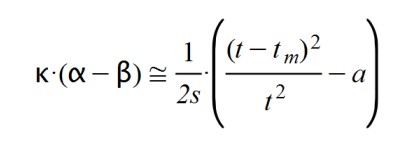
Esta forma cuadrática reúne todas las consideraciones anteriores y es fácil de tratar analíticamente. Antes he dicho que:
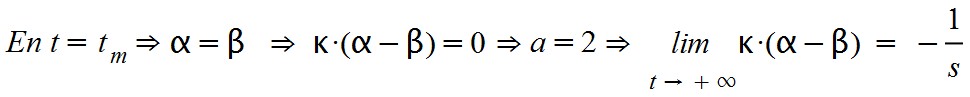
por lo que:

Ahora procedemos a resolver la ecuación diferencial de partida, es decir:
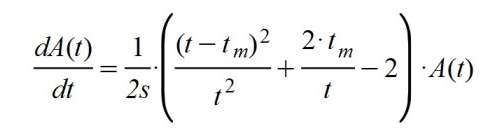
Esta ecuación se resuelve cambiando de miembro, como hice anteriormente, la función A(t) y el término dt, y luego integrando ambas partes.
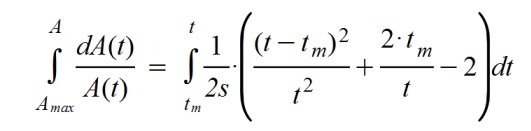
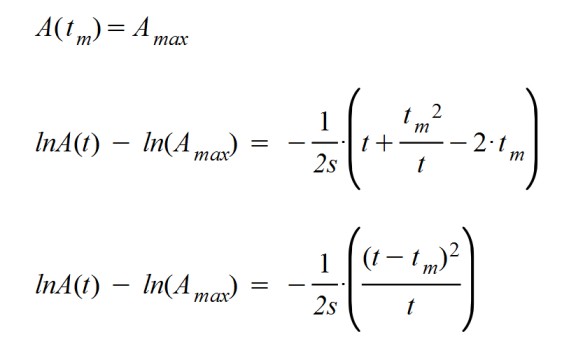
Y, como consecuencia del cálculo, se llega a la función inicialmente propuesta. Se parece a la clásica campana de Gauss... pero con el denominador del exponente dependiente del tiempo, como si la desviación típica de una curva gausiana aumentase con el tiempo.

Ahora el problema radica en acertar en el ajuste de los parámetros. Debemos conseguir que la función se ciña bien a los datos diarios. A continuación reviso la ecuación diferencial inicial para comprobar que la función A(t) se ajusta correctamente a ella:
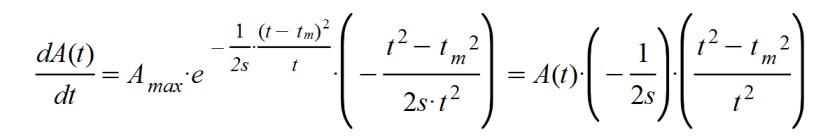
Según lo obtenido, parece que el cálculo es coherente.
Avanzamos un paso más en la interpretación de la función:
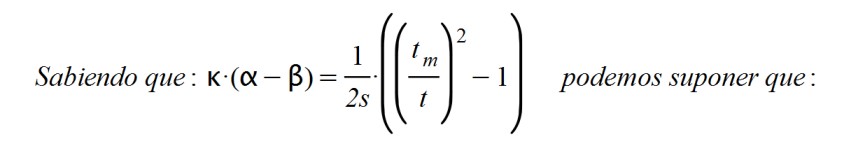

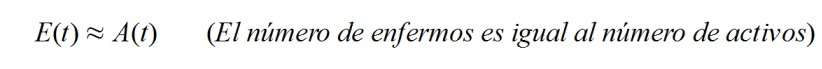
Por otra parte, sería bueno que pudiésemos averiguar cuándo sucederá el "pico" de la curva y cuánto se abre al principio de todo. Esto sería ideal para tomar medidas de contención y plazos de cuarentena.
Durante los primeros días esto va a ser complicado de acertar puesto que hay mucha variabilidad en los datos obtenidos. Conforme pase el tiempo (y siempre que se recojan los datos con exhaustividad), mejorarán las predicciones. Para conjeturar el punto de máximo tm, opero de la siguiente manera, tomando incrementos en lugar de diferenciales, y siempre como aproximación.

Así, he obtenido el tiempo en que sucede el máximo de la función A(t). Ahora solo queda ajustar dos cosas de ella: Amax y s. Ambos parámetros se adaptarán según sean los datos diarios. Estaría bien contar con software informático que pudiese realizar la interpolación de forma adecuada. También diré que los datos oficiales adolecen de sistematicidad: unas veces se cuentan de menos, otras se cambia de criterio y, en ocasiones, aparecen saltos de "fin de semana" que impiden una correlación informática eficaz. El trabajo "artesanal" puede ser incluso más adecuado que el "automático".
He dejado sin explicar el significado del parámetro "s" desde el principio. Llegados a este punto tenemos recursos suficientes para darle sentido a este valor.
La variable "s" es un número siempre positivo (s > 0); de lo contrario significaría que la epidemia se escapa de control. Expresa la "debilidad" del confinamiento y de otras medidas que impiden la propagación de la epidemia. Cuanto mayor es"s", más debilidad muestra el sistema. A mayor "s", más tiempo demorará en alcanzarse el control de la situación y más casos habrá que reportar cada día.
Si atendemos a la dimensionalidad de la fórmula, "s" viene siendo un período de latencia o de demora, un tiempo en que la enfermedad no es atendida. Según esto, cuanto mayor sea este tiempo de latencia, más tiempo llevará alcanzar el máximo epidémico.
Como este valor es un divisor del exponente, entendemos que es una variable muy delicada de ajustar. El número de afectados es muy sensible a este parámetro y, por tanto, cambia notablemente ante pequeñas variaciones de "s". Por eso resulta difícil de ajustar la función al principio de la epidemia: la eficacia de las medidas sociales que se toman (y que varían de dureza con el tiempo), tienen un efecto sustancial sobre esta variable y, por ende, influyen dramáticamente en la función de afectados A(t) a largo plazo. La incertidumbre en la evolución de la epidemia es, por tanto, muy elevada en las fases iniciales de la misma.
Recordemos que, al conocer la forma de A(t), se pueden contabilizar las otras magnitudes planteadas al principio del cálculo:
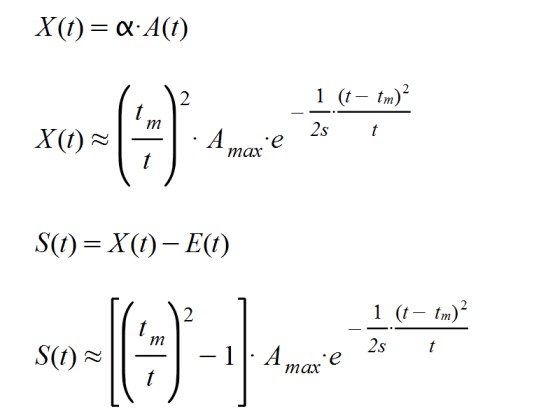

Con todo lo anterior voy a considerar el caso especial en que β < 1, o sea, E(t) < A(t). Esta situación acontece cuando el número de enfermos tratados es menor que el número de personas activas y tenidas en consideración como tal. Esto equivale a que hay personas activas que no se están teniendo en cuenta como verdaderos enfermos y, por tanto, no están siendo tratadas y podrían estar propagando la enfermedad.
También sabemos que el factor k.(α - β) es consustancial al tipo de enfermedad porque marca la proporción existente entre la variación de los casos afectados respecto de total de afectados diariamente. Recordemos que:
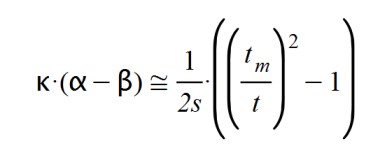
Según esto, el pico de la enfermedad sucede cuando t = tm, ya que el paréntesis vale cero, y la derivada dA(t)/dt se anula. Pero esto sucedía si β = 1. ¿Qué sucede si 0 < β < 1? En este caso procedo a simplificar expresiones y reordenar los términos:
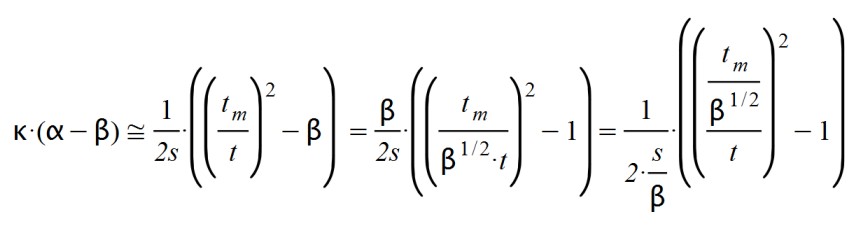
Y obtenemos nuevos valores para el tiempo de latencia y para el tiempo de máximo:
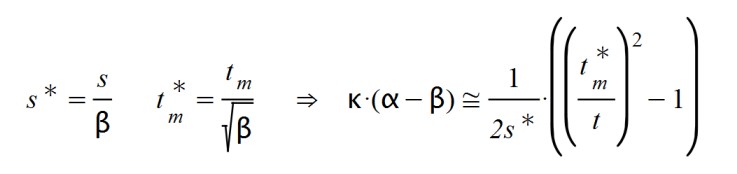
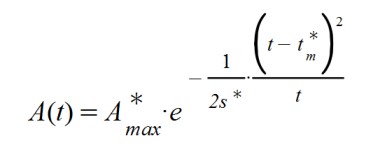
Con lo que observamos dos alteraciones directas en la fórmula de A(t) y otra más indirecta. El efecto de disminuir el valor de β por debajo de la unidad conlleva a que el tiempo en alcanzar el máximo de la curva se amplifica.
También aumenta el valor del tiempo de latencia, con lo que los efectos de la epidemia serán más duraderos. Indirectamente sabemos que se incrementará el valor de Amax, en número de afectados justo en el pico.
He aquí un ejemplo revelador: si β = 0,5. En este caso, el tiempo en alcanzar el máximo se amplía un 41% y la latencia es el doble del caso ideal (con β = 1). Por supuesto que el número de casos será espectacularmente mayor, pero queda indeterminado en función de la crudeza de la enfermedad (este es el efecto indirecto).
Esta reflexión conduce a pensar que no hay muchos casos de enfermos asintomáticos que se excluyan del cómputo. Me refiero a casos que no han hecho los test PCR (ni ninguna otra prueba), para saber si han contraído la Covid-19 pero que si la tienen o la han tenido. No creo, pues, que la infección esté tan extendida como dicen algunos. Más bien creo que esta enfermedad se está contagiando más en entornos donde se está en contacto con casos afectados, es decir, en centros médicos, residencias de ancianos, cárceles y otros lugares de riesgo por confinamiento con mucho tránsito de personas.
Habría que calcular X(t) para tener una estimación más concreta de la cantidad diaria de personas que se exponen al virus.
Aquí dejo las fórmulas complementarias que completan el estudio:

Habrá un momento en que las medidas de seguridad tomadas ante la epidemia (que se propague siguiendo este modelo), se relajen. No es posible mantener un aislamiento estricto de la población durante mucho tiempo. Así que, con cierta probabilidad, volverá a haber un número suficiente de casos que se escapen del control sanitario y las personas que tadavía no estén inmunizadas se volverán a exponer. Algunas de ellas contraerán de nuevo la enfermedad y la expandirán exponencialmente de modo encubierto (más si cabe en este caso del SARS-CoV-2, que tiene un período donde el infectado no tiene síntomas pero resulta contagioso).
Una de las hipótesis de partida era que la mayoría de la población al inicio de la epidemia no estaba inmunizada. Por este motivo, y mientras se mantenga la validez de la hipótesis, habrá una recurrencia de la epidemia y se volverán a producir picos más o menos potentes.
Estimo que esta recurrencia tiene cierta monotonía si se retoman las medidas estrictas cuando se detecten los nuevos ascensos. De no retomar medidas restrictivas tendríamos evoluciones dramáticas y extensas en el tiempo, ya que esta enfermedad presenta un largo período de convalecencia. Los casos activos que desarrollan síntomas moderados y graves tardan bastante tiempo en salir de la lista de afectados (a estas alturas creemos que la media se sitúa entorno a los 30 días).
A continuación se muestra la gráfica de la posible evolución de los casos activos "A(t)" en Corea del Sur.
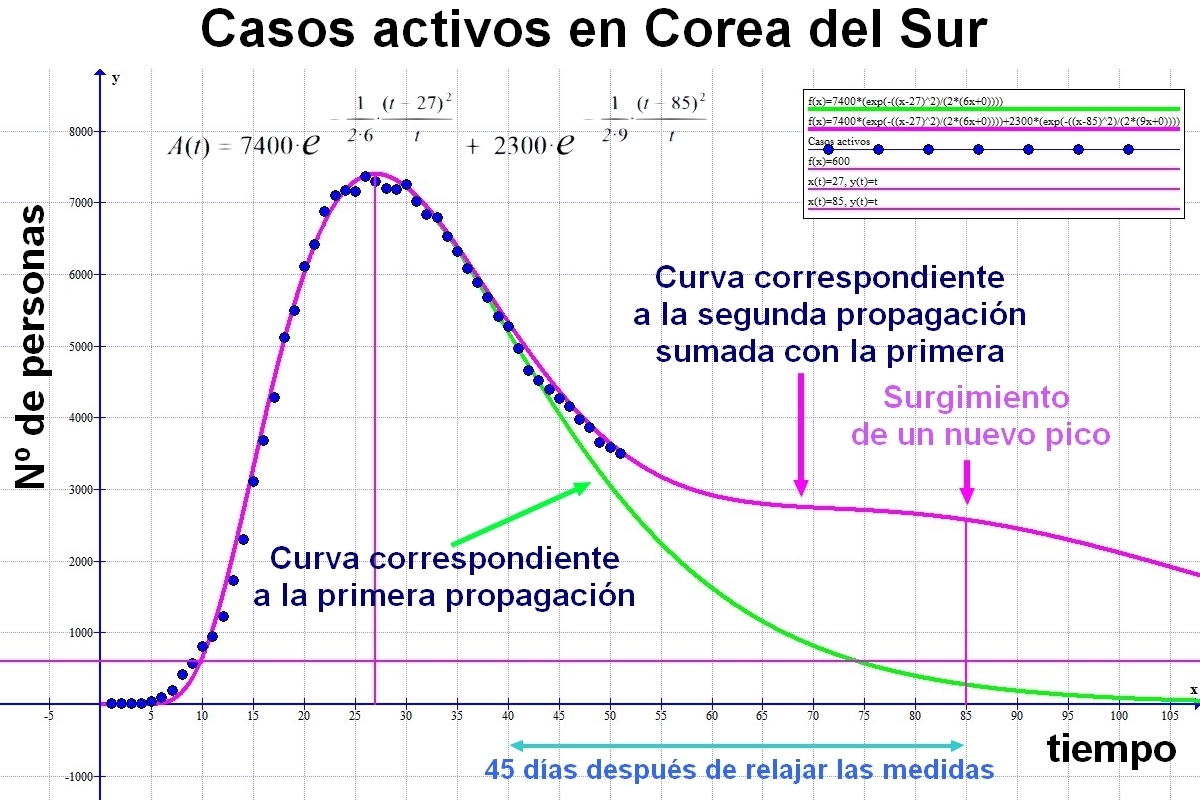
Teniendo en cuenta que el primer pico se ha producido al cabo de unos 45 días, y que las medidas de seguridad se podrían moderar 20 días después del máximo, sería factible que el siguiente pico se produzca 45 días después de levantar significativamente las medidas de confinamiento. Esto conduce a una frecuencia aproximada de 65 días entre picos. Como seguirán vigentes algunas de las medidas antipropagación observaremos que la primera curva no se relaja tanto como era previsto y que la segunda entra en el recuento como una estabilización a niveles mayores de lo esperado inicialmente con un solo pico.
Si las medidas se relajan todavía más veremos como se desarrollan picos más o menos suaves a lo del tiempo de frecuencia cada vez más difícil de determinar. Al final tendremos una propagación sostenida de la epidemia, bien hasta que se inmunice la población o bien hasta que se encuentre una vacuna u otro sistema eficaz que extermine al patógeno.
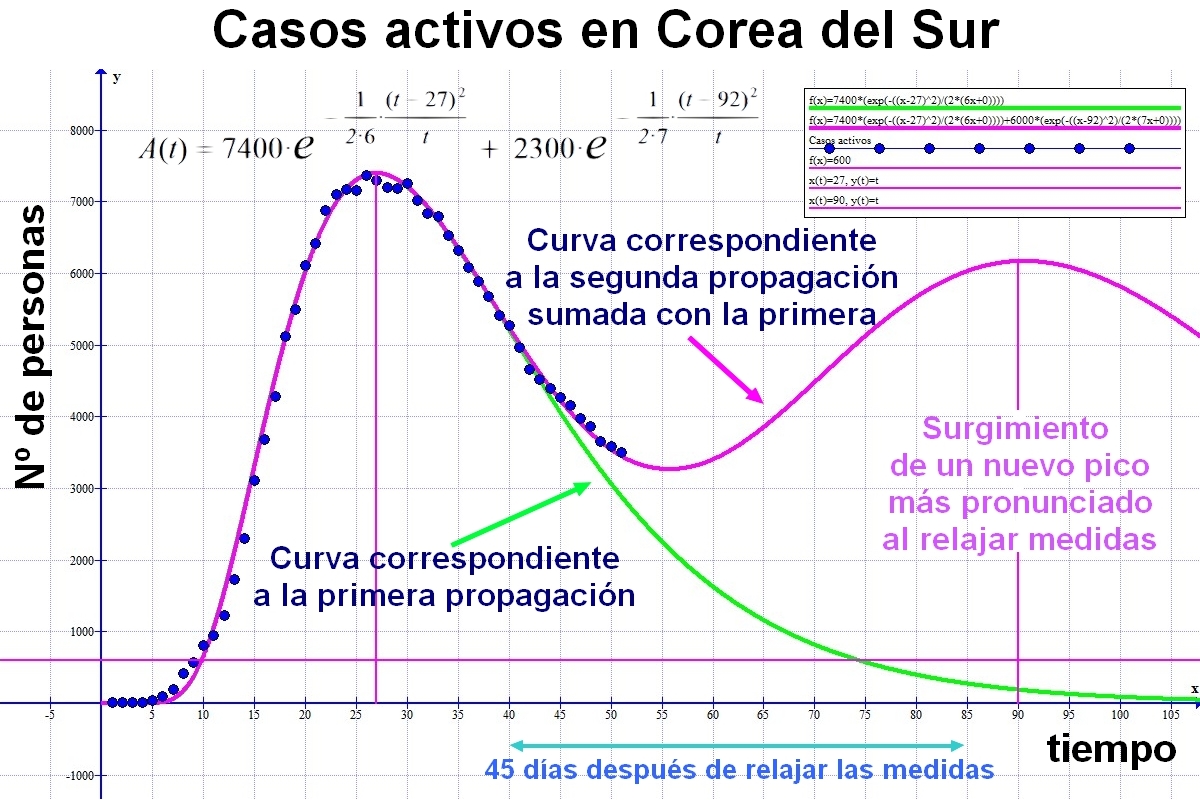
Téngase en cuenta que la función de casos activos A(x) actúa como una onda solitón que se puede desplazar en el tiempo. Este tipo de funciones son perfectamente sumables ya que su amplitud máxima no depende del tiempo y el parámetro de latencia s es adaptable. Con esto quiero decir que varias funciones A(x) de distintas localidades próximas se sumarían para dar lugar a la función A*(x) conjunta de todas ellas.
A medida que pasa el tiempo he observado como los sucesivos picos van aumentando de anchura. Parece como si s incrementase paulatinamente su efecto inicial. Esto implica que la transmisibilidad no será la misma en sucesivos repuntes que vayan surgiendo en un lugar determinado y así debamos introducir un parámetro s más pequeño cada vez que se produzca un nuevo pico.
Si deseamos mantener el parámetro s idénticamente ajustado a distintos instantes de la evolución de la pandemia debemos recurrir a la siguiente expresión para A(t):
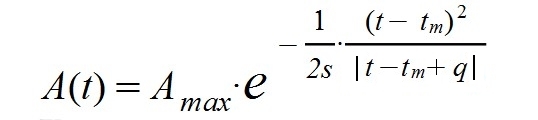
Esta función es desplazable en el tiempo y conserva las buenas propiedades de tener una amplitud máxima -y ahora una transmisibilidad- independientes del tiempo.
Hemos reemplazado la variable t en el denominador del exponente por t-tm+q, un término temporal ligeramente desfasado respecto del numerador. Para cada nuevo repunte aparece un parámetro adicional q. La diferencia (tm-q) viene a ser el tiempo de inicio de la campana epidémica de infectados o activos, que sucede unos días antes del pico tm. El valor de q implica un adelanto de al menos tres unidades de tiempo respecto del tiempo de pico tm para que la función tenga un comportamiento coherente (hay que esperar un tiempo q para que se produzca el crecimiento exponencial inicial, un tiempo de expansión). Usualmente, para la Covid-19, este tiempo q toma valores entre 20 y 70 días, siendo más frecuente un valor de 45 días. El cero del denominador se adelanta q unidades respecto del cero del binomio cuadrático del numerador, pero debemos evitar este cero para que algunos programas de cálculo no den error. Una forma sencilla de hacerlo es escribiendo q en forma decimal en vez de poner un número entero de días (es decir, q=40,01 en lugar de 40, por ejemplo).
En definitiva, que la fórmula propuesta implica una estandarización del tiempo para los sucesivos picos que puedan sobrevenir. Entendemos que existe un tiempo estándar particular para cada pico que se puede definir como: t* = t - tm + q. De este modo se puede sustituir la diferencia t - tm por otra más particular: t - tm = t* - q. De este modo el máximo sobreviene q días después de haber empezado la propagación.
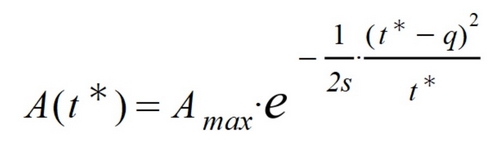
Esta función se puede generalizar para los distintos brotes y expansiones que se puedan producir con el paso del tiempo. Cada pico i-ésimo vendrá caracterizado por tres parámetros: una amplitud máxima (Amax)i, un tiempo de transmisibilidad si y un tiempo de máximo qi. La expresión general para describir la evolución de la pandemia queda así:
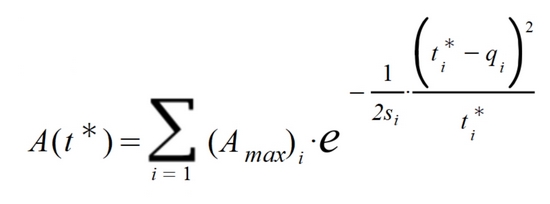
Los diferentes períodos infectivos que vayan aconteciendo se podrán seguir ajustando por interpolación a estas sumas de funciones (centradas en sus respectivos instantes de máximo), solo adaptando convenientemente los parámetros para cada nuevo caso.
NOTA:
Caben otras posibles parametrizaciones para describir la dependencia entre dA(t) y A(t), pero hemos visto que no se adaptan tan bien a los datos reales. Por otra parte, su amplitud máxima depende del momento en que se produzca por lo que son más difíciles de universalizar. Sea por caso:
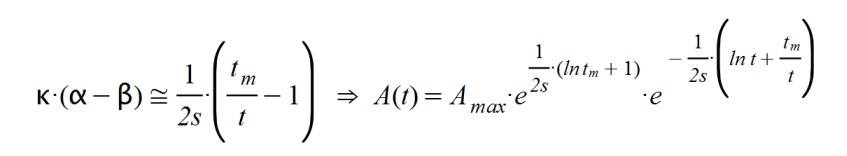
Que presenta una ascensión más pronunciada al principio de la epidemia que no se ajusta tan bien a los datos empíricos.
Relación entre los nuevos parámetros tm, s y los tradicionales Ro, τ (ritmo y período reproductivos)
Los epidemiólogos utilizan en sus análisis muchos parámetros según sea el modelo empleado. En la mayoría de modelos de evolución exponencial de una epidemia los expertos emplean el Ro, o ritmo reproductivo básico. Con él expresan aproximadamente la cantidad de contagiados que produce cada persona afectada al inicio de la epidemia. Si el Ro es menor de la unidad entonces el número de contagiados descenderá y la enfermedad se considerará bajo control. Y al contrario, si es mayor que uno la enfermedad se seguirá agravando. Ro es una cantidad difícil de determinar porque no es constante en el tiempo. Depende mucho de la severidad en las medidas de contención tomadas y también de la fecha de inicio de la epidemia (y de otros factores). Por eso se suele determinar "al vuelo", dividiendo el número de contagiados diarios entre el número de altas. A este número no se le debe llamar Ro sino R (o ritmo reproductivo a secas).
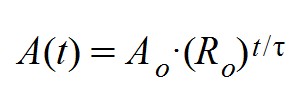
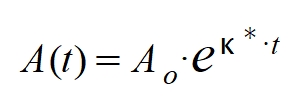
En las fórmulas precedentes se observa un modelo de crecimiento exponencial de casos activos. En la primera se establece Ro como base de la curva exponencial y el exponente τ como un período reproductivo (t es la variable temporal). La segunda fórmula es equivalente a la primera pero se ha normalizado a la base neperiana. De relacionar las dos fórmulas se obtiene la siguiente expresión para la tasa de crecimiento logarítmico k:

Recordemos que durante la explicación de nuestro modelo habíamos obtenido otra expresión para k que era de la siguiente forma:
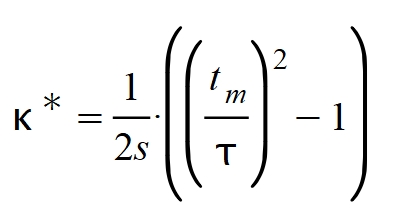
De donde se deduce que: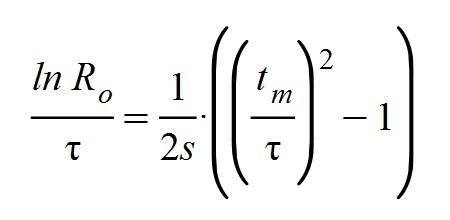
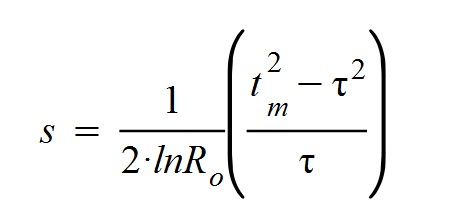
Despejando y simplificando términos se llega a la siguiente expresión para el período reproductivo τ:
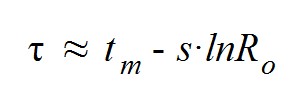
O, visto de otra forma, para el parámetro de transmisividad s:
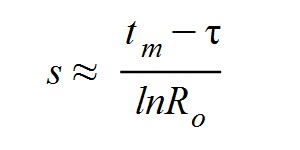
Hasta aquí hemos visto como se pueden relacionar Ro y τ según nuestro modelo. Pero también demostraremos que existe un camino para obtener tanto Ro como R y que este trabajo se puede realizar de forma sistemática y coherente con la parametrización de la epidemia. Esta idea tiene la ventaja de que permite comparar diferentes regiones (con sus peculiaridades geográficas y singularidades sociales), mediante la elaboración de estudios convenientemente ajustados en los mismos términos matemáticos.
Nuestra propuesta consiste en extraer R del cociente entre el número de expuestos y el de activos en cada instante: R = X(t)/A(t). Resulta evidente que el máximo de casos activos sucede cuando R=1 y, por tanto, ese pico se espera cuando t = tm, porque X(tm) = A(tm). Si esto es así se tiene que S(t) = X(t)-A(t) alcanzará su primer máximo en el tiempo que denominamos t':

Quedando el número reproductivo básico caracterizado por la siguiente expresión:
Para los instantes iniciales de la propagación, según esto, R tomará valores altísimos que no son relevantes para evaluar la propagación. Consideramos que es más adecuado tomar este valor para Ro por el mero hecho de que su evaluación es trivial y con poco margen de error (se basa en evaluar un punto de máximo en una función).
Por otra parte se puede contrastar la solidez del parámetro Ro al tener dos formas de evaluarlo. Me explico, también se puede obtener a partir del primer punto máximo de S(t). Supongamos que se produce en t', y así tendremos lo siguiente:
Ro = X(t')/A(t') & Ro = (tm/t')2
Por lo que ambos valores deben coincidir. Si la coincidencia no se produce será porque no hemos estimado adecuadamente el punto inicial de la epidemia. Habrá un desfase temporal que impide ajustar el valor de Ro correctamente. Esto permite estimar el tiempo que lleva propagándose la enfermedad independientemente de cuando se empezaron a consignar datos. De forma indirecta hemos establecido un punto de referencia teórico para el inicio de la epidemia.
Ahora vamos a relacionar el tiempo de máxima intensidad de la enfermedad t' con el período reproductivo τ del que hablabamos anteriormente. Hemos llamado "r" al cociente resultante de dividir estos dos tiempos:
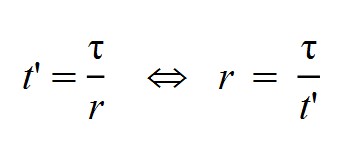
De aquí se deduce una relación entre Ro, el período dreproductivo y el tiempo de máxima expansión de casos activos tm:
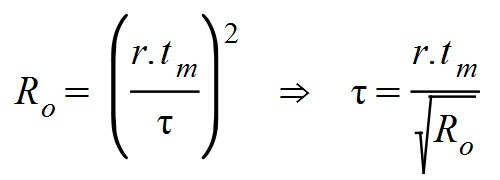
De la fórmula precedente se puede extraer una aproximación para la transmisividad s, ya que dependía de tm y de τ:
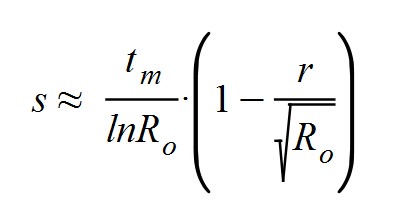
Esta fórmula es muy importante si queremos ajustar el parámetro s que hasta ahora solo se podía determinar mediante regresión estadística. Ahora descubrimos que s es directamente proporcional a tm (cuanto más tarda en aparecer el primer pico de A(t), más grande será s), y que también tiene una dependencia complicada con Ro. En principio, el coeficiente r (recordemos que r = τ/t'), debe ser ligeramente inferior a la raíz cuadrada de Ro (ya que s tiene que ser positivo). De este modo podemos establecer una cota inferior para Ro:
Ro = (tm/t')2 > r2 = (τ/t')2, (ya que tm > τ)
Hasta aquí hemos considerado una aproximación conveniente para Ro. Para establecer un valor teórico de R, la tasa reproductiva que es variable con el tiempo, nos basta con hacer el siguiente cálculo:
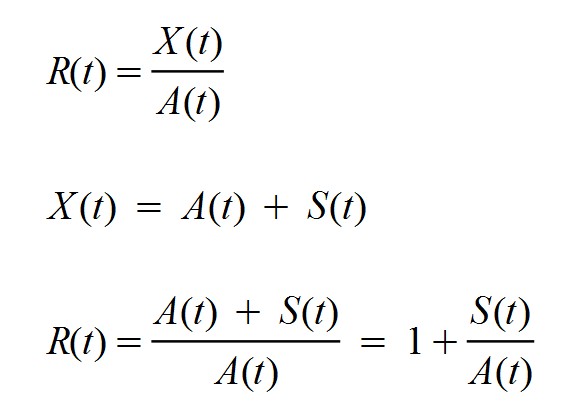
Notemos que, según esto, la tasa reproductiva vale 1 cuando la función S(t) se anula:
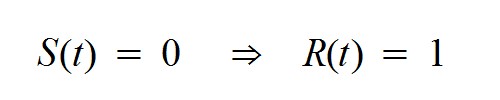
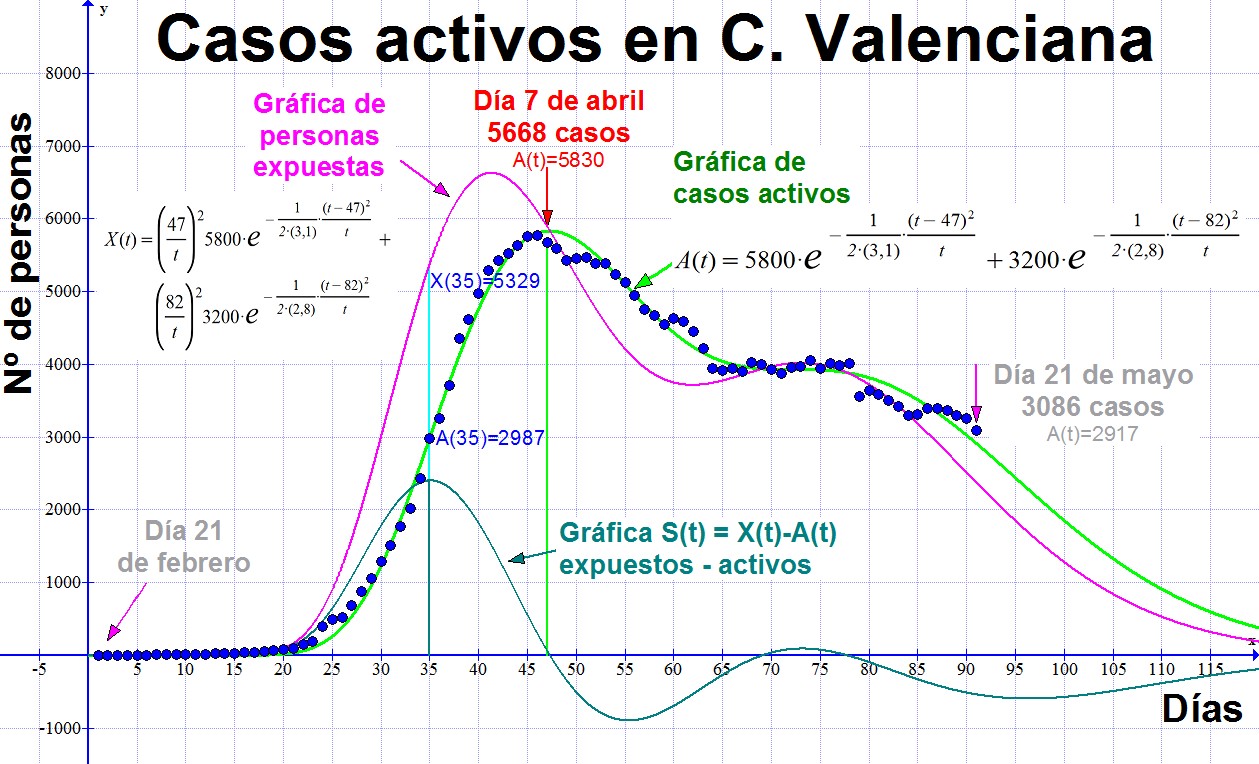
Hasta aquí hemos expuesto la parte más tórica del trabajo. Pero lo ideal es contrastarlo con algunos casos particulares para ver si se ajusta bien o mal a ellos. Hemos aplicado el modelo a varias regiones y hemos observado otra ventaja en él. A medida que pasa el tiempo pueden ocurrir rebrotes que sería muy conveniente predecir. Hemos visto que la aditividad de las funciones A(t) es congruente. Los valores reales se ajustan bastante bien si sumamos funciones Ai(t), cada una con sus tres parámetros específicos: Amax, s y tm.
Por ajuste de datos definimos para cada caso una nueva función A(t). En consecuencia aparecen nuevas expresiones para X(t) y S(t). Observamos que S(t) fluctúa entre valores positivos y negativos. Cuando sucede que S(t) = 0, entonces aparece un máximo en el número de casos activos. Si observamos el comportamiento de esta función podremos prever la aparición de rebrotes. Esto es posible tras identificar en su grafo una tendencia de crecimiento que conlleve cruzar el eje de abscisas (que será cuando la función pase de valores negativos a positivos).
Hemos ejemplificado este análisis con los datos de la Comunidad Valenciana a fecha de 21 de mayo de 2020. En la gráfica se observa que S(t) alcanza un máximo en t = 35 (el 26 de marzo). Para ese día hemos continuado el cálculo teórico con los valores obtenidos de la función (no con los datos reales). Así llegamos a que:
Ro = X(35) / A(35) = 5329 / 2987 = 1,8
Según lo expuesto anteriormente, se tiene que el primer máximo para A(t) ocurre cuando tm = 47 (el 7 de abril). Esto implica que Ro = (47 / 35)2 = 1,8. De este modo hemos confirmado la coherencia de dos parámetros: tenemos un valor consolidado de Ro=1,8 y también un inicio temporal de referencia (el día 21 de febrero, que es el valor adecuado para la parametrización funcional de la epidemia).
A continuación muestro el caso de la Covid-19 en Galicia.
Antes de nada, destaco el período de tiempo (últimos días de abril) en que los datos reales no se ajustan a la curva (ver más adelante), debido a algún cambio de criterio administrativo. Supongo que se contaron excesivos casos por test rápidos que, al fin y al cabo, no fueron efectivos (no alcanzaron la fiabilidad de la prueba PCR y se desecharon). Pudo suceder que existiese una norma de no dar altas médicas a los afectados hasta pasado cierto plazo. Sea como fuere, se han obviado esos datos.
Hemos encontrado que el día 27 de febrero cumple con el criterio de punto de partida ideal. Lo comprobamos hallando el tiempo en que sucede el máximo de S(t) que es t' = 30 días. Luego procedemos del siguiente modo:
Ro = (tm/t')2 = (45/30)2 = 2,25
Por otro lado:
Ro = X(30)/A(30) = 6280/2791 = 2,25
O sea, que la coincidencia es óptima y las gráficas tienen un punto de partida adecuado.
Los parámetros de la curva A(t) son:
Amax = 6000 casos
s = 4,9 días
tm = 45 días
Con ellos se obtiene que:
τ = tm - s.ln(Ro) = 45 - 4,9.ln(2,25) = 41,0 días (el período reproductivo)
Y se comprueba la consistencia del cálculo hallando la transmisividad s a partir de los parámetros anteriores:
s ≈ 45/ln(2,25)·(1 - (41/30)/(2,25)^(1/2)) = 4,93 días
Pulsando sobre este enlace accederemos a la página web donde se pueden ver las gráficas correspondientes a las 17 comunidades autónomas de España y también la nacional.
Relación entre casos activos, altas-bajas diarias y la tasa reproductiva R
En esta sección calcularé la relación que existe entre la función que registra los casos activos en una fecha con la función que estima las altas o bajas que se dan en ese día concreto. También he encontrado una relación entre estas magnitudes y la tasa de reproducción instantánea R(t).
En la primera parte de este artículo obtuve una fórmula para los casos activos en un tiempo dado que también se puede escribir en un tiempo aumentado en una unidad:
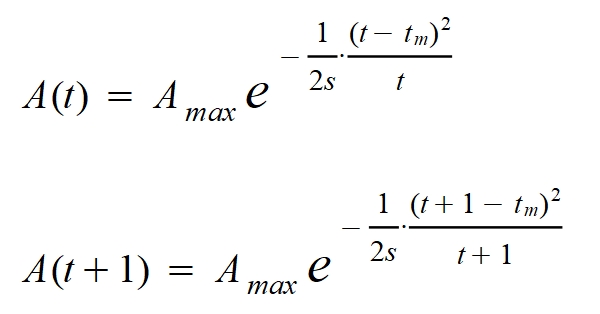
Ambas expresiones se pueden relacionar tal como sigue:
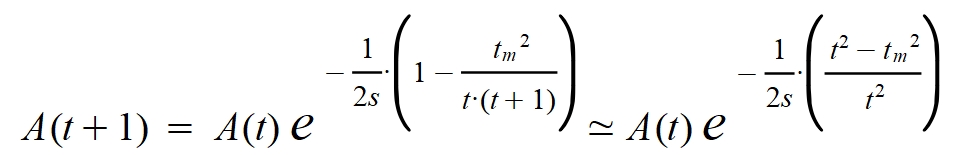
A la diferencia entre el número de casos activos en el tiempo (t+1) y los casos considerados en el tiempo t les llamaré número de altas o bajas diarias:
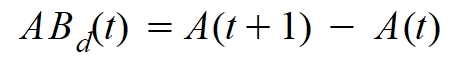
De este modo se obtiene la siguiente expresión para el número de altas/bajas en un día:
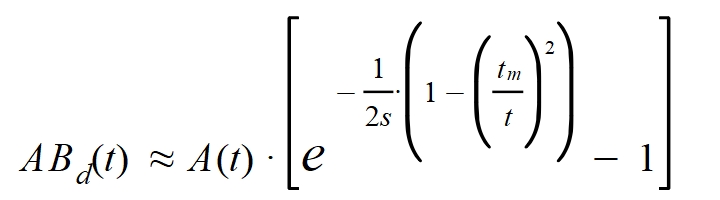
Esta función no se ajusta muy bien a los datos reales porque dependen mucho de factores humanos que impiden una estabilidad o uniformidad estadística. La tomaré como un comportamiento promedio a lo que se anota diariamente como altas o bajas en los registros de la epidemia.
Por otra parte, debemos echar mano de cálculos anteriores que nos permitían establecer las siguientes relaciones, ciertamente aproximadas:
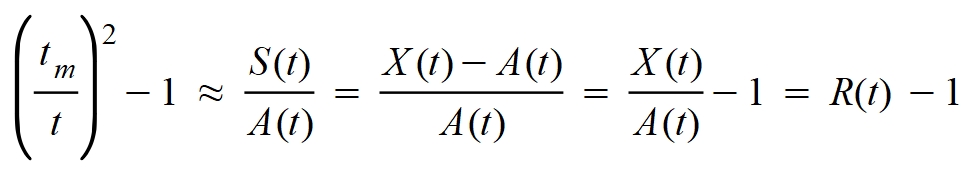
Mediante esto cambiaré las variables temporales por el parámetro R(t) y quedará la función de altas-bajas diarias del siguiente modo:
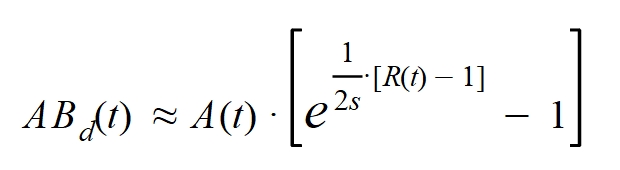
Finalmente despejo la tasa de reproducción:
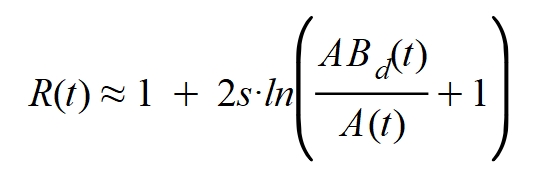
Así resulta fácil calcular este número reproductivo teniendo en cuenta los datos oficiales y se podrá estimar el valor del parámetro de transmisibilidad "s" para ajustar de forma más certera las fórmulas a los datos reales. Se observa de este resultado que en el momento en que las altas igualen a las bajas R(t)=1. Cuando hay pocos casos activos el valor de R(t) es positivo y elevado y señala que la enfermedad se está propagando aceleradamente. Las bajas cuentan negativamente por lo que el argumento del logaritmo será un decimal entre cero y uno lo cual implica que el logaritmo también será negativo y R(t) bajará de la unidad. Cuanto más baje R(t) de uno mejor evolución tendrá la enfermedad. La efectividad de las medidas paliativas se reflejan muy bien en este parámetro.
La dependencia de R(t) con la transmisibilidad es compleja ya que el cociente de altas-bajas diarias con los casos activos se hace grande con transmisibilidades bajas y viceversa. Lo que se concluye con mejor acierto es que a mayores valores de "s" el valor de R(t) se mantiene más estable y varía menos con el tiempo.
Después de observar algunas gráficas de diversas regiones he llegado a la conclusión de que la transmisibilidad depende de los siguientes factores:
Aumenta con la dispersión de la población y, por tanto, tambien aumentará si se toman medidas que incrementen el distanciamiento social. Es pequeño en pequeñas poblaciones concentradas y se hace mayor según aumenta el tamaño de la población y su dispersión. Por este motivo será mayor en un país entero que considerando partes del mismo.
Aumenta con el período de curación de cada enfermedad. Enfermedades largas tienen mayores valores de "s". La resistencia biológica a un patógeno varía entre diversas poblaciones. Las que ofrecen más resistencia se contagian en menor medida y se curan antes por lo que en sus gráficas la transmisibilidad será inferior.
La falta de medidas paliativas, la escasa concienciación social o las negligencias políticas implican mayores valores de "s".